摘要:Google 在2018年公布BERT的工作之后,引起了NLP学术圈以及工业界的极大关注。无论是在各个公司的应用场景中,还是在一些公开的 Benchmark 上,BERT的效果都得到了验证。所以国内很多公司都在跟踪BERT的研究,并基于自己实际的业务场景做了针对性的调整与应用。
本文首先概括介绍了BERT和后续扩展工作(BERTology),接着介绍了美团如何训练BERT以及在实际业务场景中的BERT应用案例。第三部分主要美团如何在搜索相关的场景的任务上中落地BERT应用。此外我们将讲座中比较有价值的问答内容也做了整理,希望也能解答部分读者疑问。

作者简介:王金刚,博士,研究方向为自然语言处理。在AAAI,IJCAI,SIGIR,EMNLP、TKDE等顶级会议和期刊上发表十多篇文章,同时也是SIGIR,CIKM,AAAI的审稿人。王金刚2018年底加入美团NLP中心,负责美团本地生活服务领域预训练语言模型工作以及情感分析相关业务。
一、BERT的介绍NLP预训练发展史
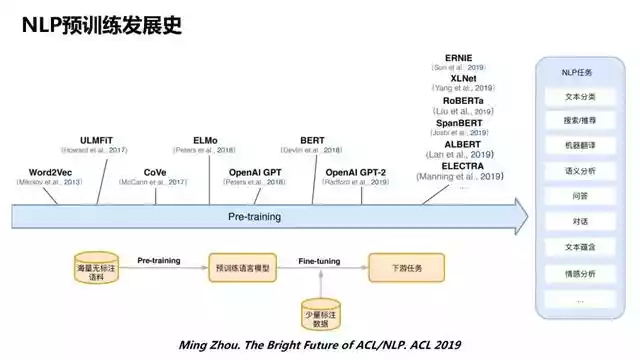
先来回顾一下NLP的发展史,上图来自微软亚洲研究院周明在ACL 2019大会上的keynote演讲。虽然有时候大家会说BERT是横空出世,效果特别好,但这方面的工作并非一蹴而就。
这方面最早的研究是大家很熟悉的Word2Vec,在NLP的几乎所有任务中都会有应用。最开始大家可能是用one-hot向量来初始化一些NLP的任务或者网络,但Word2Vec出来之后,基本上大家就都改为使用这个稠密的向量,用Word2Vec来初始化NLP的网络。
之后一直到2018年,Allen AI研究所的ELMo问世。相对于Word2Vec,ELMo不再是静态的Word Embedding,而是会考虑上下文的影响。随着算力增加,GPU硬件资源越来越好,模型也就可以做得越来越深、越来越大。所以OpenAI 关于 GPT的工作就出现了。GPT其实比BERT出来得要更早一些,但是由于它宣传方面没有Google的声音大,所以导致大家更关注后来BERT的工作,对GPT可能没有那么关注。后来OpenAI看到BERT取得这么大的关注和成功之后,就又搞了GPT2,把层数加深到24层。
BERT后续的一些发展也列在图1时间轴的最右边,包括国内的百度和清华关于ERNIE的工作,然后还有Google的XLNet。后来还有一些基于BERT的各种扩展。
BERT彻底火了之后,对NLP的学术研究和产业应用带来了根本上(或者说是研究范式上)的变化。NLP领域可以做到像CV领域一样,用大量的图片数据(如ImageNet数据)做预训练模型,应用到自己具体的任务。CV领域中,如果要做目标检测或图像分割,可以基于预训练模型做个简单的Fine-tune,然后在只有少量标注样本的目标任务上取得很好的效果。
BERT相关预训练模型出来之后,我们也可以做到通过预训练语言模型对海量的无标注语料进行学习。模型收敛之后,通用效果很好,在小量的标注样本上可以做具体的NLP任务。像分类、搜索、推荐任务中的语义分析、问答、对话,其实都可以通过小量标注样本把BERT很强大的语意理解能力迁移到具体的目标任务上。
BERT介绍

上图是BERT整个的结构,以及输入、输出。上图左边是BERT的网络结构,可以看到它有12层Transformer结构,更大的网络有时候会堆叠24层。上图中间放大了每个Transformer内部的一些结构。做NLP方向的同学肯定会对Transformer比较熟。Transformer其实是2017年,Google的论文《Attention Is All You Need》提出的。其实在2017年、2018年,BERT出来之前,Transformer的应用就非常广泛了。
大家如果做生成任务,会知道我们现在主流的模型是Seq2Seq生成模型。一个Encoder一个Decoder。最开始大家用BiLSTM、GRU,后来Transformer出来之后,我们就已经在使用Transformer了。不用说国外的Google,国内的阿里、腾讯的翻译君、百度翻译,都已经大规模迁到基于Transformer架构的翻译模型上面去了。
上图右边最上面是BERT模型的输入。输入Embedding其实有三种,它会在input这一端做一些调整。比如它除了本身的Token Embedding之外,会拼一些所谓的Segment Embedding。如果有下句预测的任务,因为有两句话,所以需要区分segment,也就有了Segment Embedding的概念。另外需要考虑的是,因为完全基于Self-Attention结构,所以需要考虑每个词在句中的相对位置,这样就会有一个Position Embedding的概念。
所谓的预训练其实就是两个任务,一个是Masked Language Model,我们简称MLM。MLM是指把文本中的某个词掩掉,通过上下文来预测这个词是什么,这个过程其实是学一个语言模型。第二个是下句预测任务,通过SEP标签拼接的两句话,做一些相关的预测。BERT主要通过这两个预训练任务的联合训练,来实现模型对自然语言文本的理解。因此,基于BERT,如果我们有一个预训练好的模型,就可以在具体的任务上做Fine-tune。

从Google官方公布来看,其实我们能做四大类任务:
第一种是句间关系任务。也就是输入两个句子,判断一下两者之间的关系。因为前面有CLS位的Token Embedding,所以可以基于CLS,接一个softmax,判断一下两个句子关系的任务。
第二种是单句分类的任务,这在自然语言推理判断文本相似度方面比较常见。单句分类是指,对输入的一句话,做一些单句分类。比如说我们业务上会有一些频道识别、意图分析,以及情感分析。
第三类是序列标注的任务,类似于NER不再依赖CLS位的序列标注,基于每个Token可以出一个预测,相当于完成整个序列的预测任务。
第四类是问答任务,类似于机器阅读理解或是抽取式问答。
以上就是基于BERT我们能做的一些主要的下游的任务。
另外BERT火了之后,大家普遍认为,因为基于BERT的扩展工作会越来越多,所以会发展出一个BERTology的概念。我们最近审的SIGIR、ACL文章的时候也发现基于BERT扩展工作越来越多,大家做得也都越来越像。

上图是清华大学刘知远老师他们组里的同学画的BERT发展关系图。可以看到早期的ELMo、BERT、GPT以及ERNIE这些名字,其实这些都是,他们起这些名字就是,基本上都是往《芝麻街》中卡通人物的名字。
我大概把这工作分了三类,因为相关的扩展不是这篇文章的重点,所以可能比较简略。大家如果对BERT的发展脉络有兴趣,可以去看一下张俊林老师《从Word Embedding到BERT模型——自然语言处理中的预训练技术发展史》这篇技术科普的文章。学术方面,最近复旦大学的黄萱菁老师也发表了一篇关于pre-train language model的英文综述论文,那篇文章对最近的工作梳理特别全面。
BERTology
下面分三部分讲一下对过去BERTology一些工作的总结。
融入外部知识
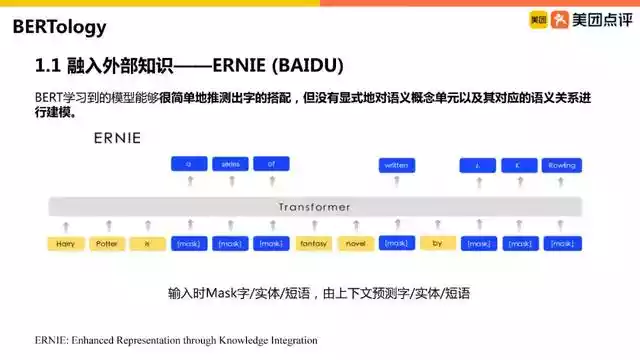
ERNIE(BAIDU):百度的ERNIE就是一个对BERT的改造。因为Google中文的BERT是基于字的,会有一些缺陷,所以百度开始做ERNIE,把MLM的任务改成掩藏一个实体,让模型预测提前识别好的实体,增强语言模型的能力。这样就不再是预测单字。因为中文更多时候表达的是完整的语言,所以需要理解实体或词。

ERNIE(Tsinghua):清华的模型也叫ERNIE,它不仅仅是基于简单的实体了,还会考虑Graph Embedding的概念。通过Graph Embedding的信息,input将其送到预训练里,而且还使用了TransE来获取Graph Embedding,融入到预训练里。

K-BERT (北大-腾讯):此后,北大和腾讯提出了基于知识的K-BERT。他们也是试图将知识图谱中的信息融入到BERT中。
更改预训练目标



ERNIE 2.0:除了加入知识以外,ERNIE后来也出了2.0版本,在训练任务上做了更多的改进,不只是包括MLM和NSP,甚至还要做一些句法结构上的预测、句子重排序、上下文等七种新的无监督任务。通过来回切换不同任务的训练,来提高预训练语言模型的通用能力。

RoBERTa和SpanBERT:另外就是影响力比较大的两个工作,Facebook后来做的RoBERTa和SpanBERT,他们会把任务变得更难一些,除了简单的掩码(掩一个单词或者一个实体),还会预测一下Span或者Entity左右的boundary在哪里?这样的话就引入了一个SBO的loss。同样他们认为NSP任务是没什么用的,所以就把整个NSP预训练任务给去掉了。其实我们在做的时候也发现,NSP任务的accuracy很快会到98%、99%,之后很长一段时间就不再涨了,所以主要训练的就是MLM任务。另外,RoBERTa加了更多的训练语料,训练的时间会更久,也有更大的batch size,并且提出了动态的mask机制,取得了很好的效果。
如果大家有兴趣的话,可以去找现在中文开源的两个版本的预训练语言模型,在上面Fine-tune一下,会比原生BERT的效果好一些。
更改模型结构

ALBERT:还有一类工作是修改模型结构。比如Google后来出的ALBERT。之前BERT模型太大、太重了,很多时候对硬件的资源要求会比较大。ALBERT相当于是对原来的BERT模型做了一些精简。

ELECTRA:在预训练语言任务里,引入了对抗学习的概念,就是ELECTRA,也有一些最新的工作。最近也有人在ELECTRA上面做了一些实验,似乎对结果有争议。我们暂时还没有跟进 ELECTRA这个工作,所以也没有结论。
二、美团的BERT实践

第二部分我来介绍一下美团在实际业务上的探索和实践,整个业务图如上,显示了美团具体的技术路线(编注:MT-BERT即美团BERT,下同)。
第一步,低精度量化实现训练加速。最初我们是有计算平台的,GPU资源也比较充分,可以从头跑预训练。美团的业务语料也比Google中文纯百科的数据大得多,在跑预训练时发现训练起来会特别慢,就尝试了做了业界内各种低精度量化的工作,其中主要是混合精度。开了混合精度之后,训练速度确实有一定提高。我们和英伟达合作较多,对方推出一些新的feature后,我们也会及时跟进、尝试,比如优化Transformer的结构,细化到一些OP层级的优化,通过这些来实现整个训练的加速。
第二步,模型预训练完成领域迁移。当我们有了一个训练好的,通用语料预训练语言模型之后,会在美团的整个业务领域进行迁移训练,相当于是做一个Domain Adaptation,当通用语料loss差不多收敛之后,开始加美团点评的业务语料,让模型来完成领域迁移。
第三步,预训练中融入知识图谱实体信息。这一步会做一些类似之前ERNIE的相关工作,我们图谱做得比较好,有一个叫“美团大脑”的餐饮娱乐知识图谱,其中的一些实体关系已经整理得差不多了。通过前面的EntityMask方式,可以利用这些实体的信息。
第四步,微调支持不同类型的业务需求。有了这些预训练语言模型之后,就可以在不同的业务上做一些尝试,支持不同业务方的需求。这里我简单列了一些(见上图),其实现在还有一些跟搜索,尤其是搜索排序业务上的合作,但是目前还没有对外发表技术文章,美团技术人员那边要求我们还是尽量讲之前发过的工作,所以挑了一些已发表的工作,待会向大家简单介绍一下。
数据和算力

预训练语料的规模可见上图。美团的客服日志是有一些对话数据的。有很多UGC,也就是用户评论。去掉一些不太好的、质量比较差的评论,仅优质点评的语料我们就有90亿规模的字,Google中文只有3亿,相比来看我们语料层面上其实是大很多。
有同学问到Horovod,那其实是Uber开源的分布式框架,我们是基于TensorFlow来做的,在多机多卡的情况下,尤其在集群的情况下,分布式训练的效率会比TF原生的分布式框架快很多。上图中右边不是我们数据,这是英伟达官方给的数据,可以看到在吞吐量上提的挺明显的。
美团 BERT 预训练

把预训练工作总结一下,主要是四点:
第一部分是低精度量化,这是为了加速训练和推理过程。精度默认是Float32类型,这会有一些不必要的传参和一些不必要的表示,会降低精度,表示成Float16类型,做混合精度的训练,对训练是有很大的加速的。
第二部分是做领域的自适应。在美团业务场景下我们有大量的语料,在原来技术上大量地对其再继续训练,实现从通用领域到业务领域上的迁移。
第三部分我们会把实体知识用到预训练里。其实这块我们没有像清华的ERNIE那样用一些Graph Embedding,我们发现尤其是在业务场景下,图谱越大,关系有时候会变得稀疏,效果反而会有影响,所以我们只考虑实体。
第四部分由于涉及到业务的上线,BERT原生base是12层,对上线的挑战很大,所以我们为了满足上线的要求做了优化,包括模型的裁剪、知识蒸馏,还有一些Fast Transformer优化,通过多种方式实现模型的轻量化。
以上我们企业工作的概括介绍,接下来依次来展开具体讲解。
混合精度加速

混合精度方面,我们开了FP32跟FP16的混合训练之后,从测试来看, 最后训练基本上是加速了两倍多,对我们的帮助还挺大的。后来我们用100多张卡的集群来跑预训练的话,跑一个base,大概一周之内基本上就收敛充分了。如果是train large的话可能也能控制到一周到两周之间,带来的提速还挺明显的。
领域自适应

上图是在通用Benchmark上跟我们自己的Benchmark上一些指标的对比。我选了ERNIE最开始用上面公开的中文的一些Benchmark数据集,比如NER的、LCQMC语义相似度的、有情感分析、有DBQA,以及自然语言推理的一些任务。首先Google BERT训练得并不充分,即使不换数据,不加数据,只是接着再跑一跑,效果就有提升,我们也加了一些通用语料进去,在Google基础上可以看到在各个任务上都有持续的提升。在我们自己的数据集上,比如说Query的意图分类、Query的成分分析,还有一些细粒度情感分析任务上,相比于Google原生BERT的指标明显提高。
知识融入

另外就是知识融入,有同学问K-BERT,其实我们的做法偏简单,我们做的就是Whole Word Masking,只不过我们的entity是取了图谱的实体。美团O2O场景的语料偏生活服务类,比图实体会有一些菜,一些大家团购的团单,所以我们会对这些词做一些遮蔽,然后用模型去预测,通过这种方式来强化预训练语言模型对场景的自适应,或者是对任务上优化的表现。
模型轻量化

如上图,为了模型要上线需要做一些轻量化的工作(编注:MBM,是Meituan -Mini-BERT的缩写),主要是两个思路:
第一个模型裁剪,如果对性能要求不是那么高的话,Fine-tune的过程中就可以减少层数,结构少了,参数小了之后,推理的时间也会变小,可能在实际场景下,上线不会像12层那么难。
第二个是模型蒸馏, Hinton做了Knowledge Distillation,后续好多人将其用到了BERT,通过BERT 12层的原始模型蒸馏一个小模型出来,蒸馏的过程中可以做很多变化,比如说层数可以减,其他参数也都可以减,通过这种方式把模型变小。我们在Query意图分类任务里直接做一个裁剪,因为我们这边的Query大部分是一些短Query,对12层模型的需求没有那么重的情况下,我们就直接继续裁剪了一个4层的小模型出来。有同学也问到整个响应时间,比如说我们在这边单Query的情况下响应时间,如果说我们用一个全尺寸的12层的话大概在13毫秒,我们做到4层之后就能降到6毫秒,基本上省了一半的时间。前面也提到还有Fast Transformer优化,来进一步压缩响应时间。
三、美团搜索场景中的应用
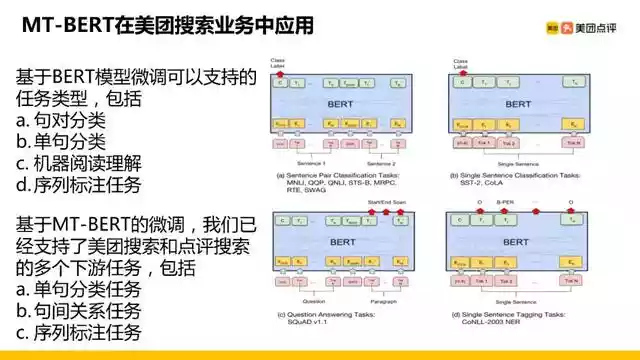
前面提到了BERT在做下游任务时可以做很多微调,从上图能看到主要有四大类,但是我们对机器阅读理解任务没有太多的业务场景,主要做了其他三类:单句分类、句间关系(句对分类)和序列标注的任务。

上图概括了我们不同的业务场景分为单句分类、句间关系和序列标注三种任务类型。尤其在搜索场景下,大量的需求是做响应召回,之前可能只需用DSSM来做,现在也想试一试基于BERT,用Embedding做向量召回或者相似度的计算,所以我们基于BERT做一些编码来支持语义表示的需求。下面从单句分类、句间关系和序列标注三方面因此展开来讲。
单句分类
情感分析

首先是单句分类,先看上图是简单的情感分析,一个具体的情感分析在美团和点评的场景下,UGC占比会很高,用户会写各种各样的评价。而且每个人给分、打星级的尺度和力度,跟他写的内容有时候不太match,比如有的人倾向于给高分,但他写负分评价,这种情况下,我们就需要对句子做整句的情感极性的判断,帮助业务方过滤负面评论,完成业务上的优化。
句子级情感分析

再看上图的句子级情感分析,这块最开始是一个双向的GRU的网络,有了BERT之后,我们直接基于BERT的CLS做一个Fine-tune,上图中的数据表明效果有明显的提升,大多时候句子集的情感分析是需要离线,相当于T 1的更新就可以,这块对线上没有太多的要求,所以我们基本上是离线进行批量的处理,我们点评全量的不同业务场景下的情感分析的请求,来帮他们做负面内容的过滤,包括垃圾评论的识别和广告过滤。
细粒度情感分析
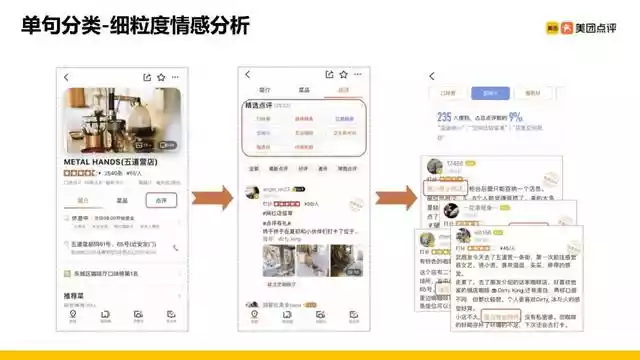
接下来讲情感分析中比较重要的工作,也就是细粒度情感分析,如果大家是点评的重度用户,你可以发现商家点评详情页有一些精选点评模块(如上图),这个模块有一些不同的情感标签,比如说口味赞、装修精美或交通不便这种稍微偏负面的标签,用户可以参考这些标签,提前做决策是否要去这家店消费。
这就涉及到需要对用户很长的一段评论,做很细的情感分析,学术界的定义是Aspect-based Sentiment Analysis,我需要判断评论在每个aspect上,是正向、负向,还是中立的。如果能把一些标签识别得很好,用户点了这个具体的标签,就能把相应的评论看一下,比如点“空间小”的标签,有一些相关的评论能出来,这对用户做选店,消费等决策有很大的帮助。

上图是2018年美团跟创新工厂联合举办的AI CHALLENGER比赛,我们把这个数据放出去过,为比赛做单独的Track。

我们的数据集的成本其实挺高,当时为了比赛,公司出钱请人去做很细粒度的标注。这块是人工定义好的,是偏业务层面的aspect,主要维度还是业务方来定,因为他们有专业知识。比如美食,要看用户会关注哪些维度,有地点、商家服务、价格、环境、菜是否好吃,当时大概有20个维度,后续也一直在扩充,维度会越来越丰富。这其实是一个四分类任务,对每个点评需要判断在aspect上来判断是正面、负面或者中性,还是压根就没有提到,这也是一个单句分类任务。

上图可以看到我们基于BERT搞了一个多任务学习的框架,现在做情感分析没太考虑图片的问题,图片会有一些多模态的问题,但是我们现在有同学在做多模态知识图谱,就把图片的信息考虑进去了。
我们回来说细粒度情感分析网络结构,有20个分类,不同的aspect会有分类。和前面句子情感分析一样,之前也是按双向GRU网络来做,后来我们把图示中间部分整个换成基于BERT做出来的Token Embedding,相当于是对20个aspect classifier做一个分类,这块我们考虑做联合训练,可以部分减轻不同aspect上数据分布不均匀的问题。
另外还有一个好处,比如说这20个aspect有足够的数据每个都能做好,但当新加一个业务的aspect进来,初期业务方只能标小量的数据,有了BERT之后,结合多任务学习的框架,即使有小量的数据,从上图能看到,我们也能做到基本比单独训练好很多的效果。

上图是我们早期的一些工作。BERT刚出来时,好多人在思考如何应用,应用方式有两种,一种是Feature-based,就像我们之前用的是Word2Vec一样,直接Embedding出来,加到之前的任务的网络里。
第二部分不论直接基于BERT CLS也好,基于后边Token Embedding也好,都可以做一个Fine-tune,到底哪种方式好?我们当时做了一个详细的实验,尤其在ABSA任务上,也就是细粒度情感分析任务,我们对比了之前比较主流的两种ABSA的方案,这是在2016年、2017年两个影响力比较大的工作。我们做了各种对比实验,基本上来看,在ABSA任务上效果比较好的还是推荐直接做Fine-tune。Fine-tune的时候我们试了基于CLS直接分类,也试了基于后边Token Embedding的方式来做。实际来看还是基于Token Embedding直接做Fine-tune,在我们这个场景下效果是最好的。
可能有人会问联合训练怎么做,这块其实有很多做法,我们做简单的,20个领域可以加一个超参,设置不同的权重再放到一起,通过数据驱动的方式来学权重。还有另外一种方式,因为不同aspect之间的关联性不太一样的,可以考虑不同aspect之间的一些relation。然后可以做一些新的正则项,或者是手动加一些权重加进去,效果就会提升。我们当时在中间又加了一层Attention网络,让它自己去学不同的权重。因为每个aspect数据量不太一样,所以通过机制来学不同的权重。
Query意图识别

接下来看单句分类关于Query意图识别的应用。Query意图识别在美团和点评两侧的搜索里是一个很重的模块。这涉及到不同业务流量的划分,比如如果本来是外卖的用户请求,你把它划分成了旅游或者是到店的请求的话,两个业务方都会来找你,这就比较麻烦。
所以我们对搜索的Query意图会有多分类的需求,上图显示了我们当时用裁剪后的BERT对比之前线上的SVM或者是一些规则的模型在指标上的提升。其中有一些是上线AB的指标,有些是人工抽检指标。可以看到在Query短的情况下,BERT相比传统模型是有很大的优势的。
推荐理由场景化分类

另外一个应用是推荐理由的场景化分类。大家如果用过点评和美团,可以看到不同的商家POI会有一些推荐理由或者可解释理由。其作用是用户搜到一个结果之后,要显示出这家店有哪些特色?为什么会被召回?或者会有一些亮点推荐。比如有一家店,如果在一些推荐场景下没有用Query,把这个店推荐给用户,可能需要一条理由,比如这家店的特色是什么,然后就是在不同的场景下,需要给出相应的推荐理由。
另外与Query相关或与用户相关,我们会做一些个性理由推送。如果大家是美团和点评的资深用户,肯定见过各种各样的推荐理由。这是因为数据的主要来源是用户的评论,不管是抽取、基于模板匹配、基于搜索、都依赖于整个的UGC的供给。

不同的业务方,需要从推荐理由本身很大的推荐理由池中做细分。比如同样是关于一家店的推荐理由,在点评上和在美团外卖的两个场景下,需求不太一样,例如在点评上搜索美食,推荐理由可以是关于这家店的服务态度怎么样、地理位置偏不偏、好不好找等等。但是在外卖的场景下,用户不太会在意这个店在哪?服务好不好?主要是看配送速度、菜的口味怎么样?这就涉及到了场景的细分。
给定一个关于这个店的推荐理由,我们需要做一种业务场景的区分,这其实也是单句分类BERT的应用场景。包括酒店推荐,我们也会有一些推荐理由,细分到酒店是否有自己的特色,删除不相关的推荐理由,这样就不会报bad case。
前面提到的推荐理由,也是一个分类任务,可以理解为关于一家店有很多的推荐理由,但是比如说这家店出现在外卖的场景下,推荐理由如果不是关于配送关于美食,出现了其他理由,比如说服务,这就是一个负例,需要把它从我的池子里删掉,这样就不会报bad case出来。
句间关系-Query改写语义一致性检测

下面介绍一下美团在句间关系场景下与点评合作的关于Query语义一致性检测的业务。
Query改写是搜索Query中很重要的组成部分。尤其像美团生活服务类业务,更加依赖Query改写,因为不知道用户会搜什么关键词。比如“游泳”,用户就可能会搜“小孩游水”、“儿童游泳”;再比如“自行车”,由于南北方言的差异,北方说“自行车”,南方就可能会说“单车”,本质上搜索的是同一事物。
Query Doc自来有一些语义上的gap,会产生上下位词的概念。比如“理发”的搜索,就会有“剪发”、“造型”和“剪头”。
另外关于一词多义,比如“结婚照”的搜索,可能是“婚纱照”,也可能是“证件照”,这两个关键词本质是不太一样的。如果改错模型的话,负面影响会特别大,比如将原本正确的例子改成错误的,导致处理的结果完全不相关,是很恶劣的bad case。所以生成改写模型之后,需要对语义是否一致进行检测。

这也是能够应用BERT的场景。比如上图的场景中,“声乐培训”、“学唱歌”两个词是改写的一个pair,经过人工review确认正确以后,作为训练样本对BERT做分类的模型进行训练。所有改写的pair上线之前,都需要经过训练好的BERT模型打分,只有模型判对,确认是同一个语义,才认为这是可以上线且符合线上要求的正确改写。如果模型判错,就可以直接去掉了。这样就可以避免线上出现很恶劣的改写的case。
序列标注-Query成分分析

最后来讲讲序列标注:Query成分分析,成分分析只是美团内部的叫法,这其实是一个NER的任务,可以应用于酒店搜索的场景中。酒店搜索场景下,有时候用户输入的Query具有一些复合目的,对 Query做成分分析,后续可以进行一些指导召回的操作。如右图,搜索的是“北新泾五星级”,这里有两个意图:第一,北新泾是地标,搜索的是北新泾附近的酒店;第二,五星级是对酒店星级的要求。右图呈现的结果其实是一个bad case,“北新泾五星级”,地理位置是对的,但是呈现了很多经济型的酒店,与“五星级”不符。
所以需要对Query做细粒度成分识别,也就是进行NER序列标注,有时还需要识别核心成分。比如电商或者是O2O的用户搜索很随意,可能只是关键词的堆砌,这种情况下就需要识别用户搜索的核心词,如果整个Query串召回没有结果,就需要进行丢词,只保留用户搜索的核心成分,然后做二次召回,看是否能够召回一些相关的结果。

我们基于BERT做了一个NER任务。之前大家做基于BERT的NER任务,效果最好的应该就是BiLSTM上面拼CRF的方法。
我们直接基于中文字的BERT模型做识别,前面对BME的标签识别,可以看到一些POI,比如上图中的一些城市。其实BERT直接Token Embedding,softmax就可以进行判断了,从benchmark指标上来看,效果差不多。
我们也试过BERT直接拼CRF,指标表现确实会好一些。这里可以和大家分享一个点:如果直接softmax,前一步相当于是每个Token Embedding进行预测,看似整体的准确率高,但是分析抽检的时候可能会出现标签跳变的case,比如本来应该是BME, E没识别出来就有可能识别成下一个标签了,这样整个的识别不完整。而如果加了CRF,bad case就会大大减少。
这是有关序列标注上的任务。前面讲的这些任务,基本上是我们2019年与搜索的业务方的合作,进行的一些尝试。
MT-BERT一站式训练和推理平台
另外再讲讲下美团的一站式训练和推理平台。由于我们组人力资源有限,我们和每个业务部分都要对接需求、对接数据需求, 还要帮助他们训练模型,做benchmark测试,最后交付,工作量比较大,对算法人力的要求特别高。
业务方的,包括算法工程师,不只是想优化业务算法,也想尝试BERT的优势,但是由于涉及到预训练语言模型核心的代码与模型,没办法减轻任务量。

后来我们就与公司工程团队合作推出一站式训练和推理平台。好多公司应该已经有了自己的机器学习平台,类似于阿里有PAI,百度有PaddlePaddle机器学习平台,美团也有一套自己的机器学习平台,我们与自己的机器平台合作,将预训练好语言模型上传,有12层的全尺寸的模型,也有蒸馏好的6层小模型,甚至也支持基于这些模型进行层数的裁剪。使用者只需要上传自己的业务数据,点几个按钮,就可以对自己的具体任务做一定Fine-tune比如平台支持一些句间关系的任务、单句分类的任务、序列标注任务等等。
我们有这个平台之后,相当于是对整个业务层面的支持,也为算法同学减轻压力、提高人力效率。


上图是早期相关的一些工作,大家可以直接去美团技术团队的微信公众号上找我们技术文章,文章叙述得比我今天讲得更加全面。
四、Q & A环节Q:数据标注大概多少?
A:如果是问关于情感分析的部分,那个数据集是为了AI CHALLENGER比赛公司花钱专门标注的一批数据,数据量特别大。如果只想问不同任务下需要标多少数据才能跑这个Fine-tune,就要看业务场景了,比较难的任务,可能需要多标注一些,比较简单的任务,可能少标几千条,效果也还能过得去,也能支持。
Q:模型蒸馏具体怎么做?
A:模型蒸馏的部分可以看一下Hinton那篇关于Knowledge distillation知识蒸馏的文章。简言之,可以把BERT看作teacher model,目标网络就是student model。同样的训练的数据,大模型是怎么预测的,小模型也学着预测distribution。这样就可以把大模型的能力迁移到小模型上去。
Q:蒸馏到什么模型?
A:我们是蒸馏到不同的小层数上,小BERT模型,但现在也有一些工作:把BERT蒸馏成一些小的CNN模型或者是其他的一些模型也是可以的。
Q:蒸馏只在下游任务做吗?
A:蒸馏不只是在下游任务进行,预训练的时候也可以进行,我们就有一个例子是直接在预训练里开了蒸馏,相当于直接预训练一个6层的小模型出来,后续不同的任务,可以直接基于6层的小模型进行Fine-tune的。
A:这个我们没有深入考虑,因为不同业务场景是具体到我们的任务上了,一旦要做蒸馏、裁剪,就已经是在考虑模型上线了,也就不太考虑泛化性,而是针对具体任务单独优化一套模型。
Q:语义模型的训练数据的覆盖度是什么样的?
A:这个问题,我不是特别清楚,因为训练数据主要还是和业务方合作,由他们提供。我不明白你说的训练的覆盖度是什么?是指覆盖线上流量吗?如果只覆盖线上流量的话,我们就用来做训练数据,基本上是按流量的分布采的,比如不同的业务流量上,我们会根据占比采一些,来实现整个业务场景的覆盖。
Q:搜索的意图识别是分类的识别吗?
A:对,搜索的意图识别主要就是分类的识别,但也会有一些类目的预测,这个工作我们也在做。这些信号我刚才也提到了,在美团和点评两边的搜索中Query understanding是很大的一个模块,这个模块会涉及到很多信号,也就是意图识别、类目预测,这些词权,都需要做。
Q:工程化的加速?
A:加速主要分两部分,一个是刚才提到的混合精度,另一个就是FastTransformer的优化,Google release的BERT中使用的还是原来的Transformer,英伟达自己的FastTransform,相当于是在OP层面做一些优化,如果基于英伟达的Transform实现BERT,推理速度会有一些提升。
Q:关于实习招聘跟正式员工招聘?
A:大家可以关注一下美团技术团队的公众号,应该是有投递邮箱,如果感兴趣的话就直接走邮箱投递就行了。
Q:蒸馏和ALBERT比较?
A:蒸馏没有和ALBERT比,我们其实后来没再尝试ALBERT,因为我们大多还是做一些业务的支持,就我今天主要介绍那些工作,后续的我们就没太follow了,没有自己去实现过。
Q:搜索可能是刚才Query的意图分类,为什么不是一些相似度?
A:其实是有相似度的任务的,但是我今天的talk没列出来,因为我们还在尝试,关于BERT怎么在搜索,尤其在relevance model使用,也是最近研究的一个热点,在SIGIR相关的一些会上,最近的文章也挺多的。但从我们自己的尝试来看,还是挺难的。Google之前发博客说,他们用BERT改善了10%的线上搜索流量,但其实是用到了精选摘要的频道,也就是Featured Snippets,比如搜索天为什么是蓝的,出来的第一个结果,会把相关文章里内容的回答摘出来,其实就可以用BERT优化,相当于是做机器阅读理解任务。但是我们的场景不太一样,所以我们就没太做机器阅读理解的任务。我们预训练BERT其实是从头开始训练的。
Q:预训练有多少卡?
A:我们公司有那种计算平台集群,大概应该是100多张卡,100张卡以上,如果只是train一个base的话会很快,因为你看训练曲线,其实三四天就收敛差不多了,然后要是跑一周的话,后三到四天,曲线就是缓慢的上升。基本上是一周内能train一个比较好的模型,large的话时间会长一些,可能得一周半到两周之间,我们这边也跑过large,但是large有一个问题在于不同任务上,large模型有时候会表现得不太稳定,所以我们尽可能是应用在下游任务。
Q:能在其他数据集上微调吗?
A:可以的,训练完可以用数据集微调,但要看数据量多大。如果是无监督的语料,其实不叫微调,那其实就是做一个continue training,这其实在早期的NLP任务里也有。比如想做一个领域的迁移,训练过程中可以分batch,整体上风险会比较大。慢慢把新的数据集加进去,作为一种领域的迁移,作为continue training是可以的。
Q:推荐理由?
A:刚才可能讲得有点快。我们推荐理由的分类,本质上是对于评论的分类,但是推荐理由我们已经针对每个商家做好了,会有各种方式,比如抽取式、生成式,也有模板类型的。比如线上的索引,就有几百条推荐理由可以用。到具体的推荐场景下或者到外卖的情况下,每个场景又不太一样,所以需要对推荐理由做一些针对业务场景的分类,也就是一个单句分类的任务。
Q:蒸馏的performance会下降吗?
A:会,在benchmark上基本会有一到两个百分点的下降,但是具体任务上能保持原模型98%左右的性能。
Q:微调有什么tricks?
A:微调好像还真没有太多特别的tricks,我觉得具体任务具体分析,可能需要看一下,一般可能就是epoch别跑太多,一般2到3个,看微调的数据量有多大,可以调一调learning rate,不同任务上可能对learningrate敏感度不太一样。
Q:知识图谱在美团业务的应用?
A:可以看下美团技术团队的公众号,之前王仲远老师有一篇名是《美团大脑》的文章,对美团知识图谱在业务上的应用进行了比较全面的介绍。我们现在BERT的工作里没有用图像,基本上还是纯文本。
Q:细粒度情感分类怎么做的?
A:细粒度情感分类,在我们的场景下是对每句话做一个多分类。
Q:多loss训练?
A:因为我们会有多个aspect的分类,比如有10个aspect category,那就是做10个aspectcategory的多分类任务,最简单的多任务学习,就是把loss简单相加。直接这样train的话,效果比单独做有提升。但是有个问题,不同aspect可能缺的数据不太一样,这样的话一些数据比较少的aspect任务可能会被带偏,所以这里需要做一些loss上的约束或者说做一些优化。其实有很多可挖掘的部分,不同aspect之间关联程度这块可以做一些考虑和尝试。
Q:句向量可以用BERT做吗?
A:可以的,我们最近也在尝试。但是有一个问题在于,BERT的原生向量维度比较高,会有768维。如果Doc量特别大,尤其是在工业的场景下,亿量级Doc的话,用Faiss也好,用其他也好,建索引的成本比较高。要是做向量召回,或是做向量相似度计算的话,EMNLP2019有一篇关于Sentence-BERT的文章在做这方面的尝试,可以看一下。另外可以考虑通过蒸馏或是其他的方式,把向量维度减下来,这样可能上线实际用起来效果会比较好。
Q:GCN的推荐场景.
A:有其他团队在做,这方面后续应该也会有技术文章发到美团技术团队的公众号上,可以关注一下。
Q:如何融合图像数据到BERT里边。A:我们现在还没做到这个层面,但是有很多相关的研究,可以去关注一下。现在做多模态的预训练语言模型,会把视觉的信号用进去,主要还是视频和图片的信息,这方面已经有好多论文可以去找一下。
Q:Query太短,BERT效果会不会好?
A:在我们的场景下对意图做分类,效果还挺好的,而且把BERT裁减到4层以后,还会比一些传统的方法的效果更好。
Q:低星好评,高星差评,具体是如何处理的?
A:我觉得这个问题是涉及到业务层面的策略了,其实我们没太考虑这个问题,主要还是对用户的评论内容,做情感分析的分类,具体怎么展示,这可能是业务层面上的考虑。
Q:数据少的aspectloss怎么约束?
A:其实可以做一些简单的实验,比如数据量少的话,希望模型多学到一点东西,其实是把它loss scale一下,尽可能在多任务里,权重会高一些,看看这样有没有效果。
Q:BERT太敏感
A:对,这个问题确实是存在的,而且也不只是BERT的问题,可能现在很多的深度学习模型都存在这个问题。做一些简单词替换的时候,分类结果或者是一些预测结果就产生了变化,这其实也是一个研究方向,怎么样提高现在预训练语言模型的鲁棒性、稳定性。
Q:多任务里面,多loss相加?
A:我们其实不是简单的相加,刚才的分享中也展示了一下,我们的模型中间会有一个attention层,去学不同aspect category之间的关系,由此来调节不同的时间权重,我们的aspect-category是预先定义好的,也就是业务上需要的aspect。
Q:地图信息团队。
A:这我还不太确定,因为现在我们的模型已经在机器学习平台上面了,所以不同的业务团队都可以使用那个模型去做一些微调,我不确定其他团队有没有在用。
Q:关于target-oriented和aspectterm
A:target-oriented 和aspect term应该都是细粒度情感分析。如果细分的话,我们做的其实是叫作aspect-category的任务,你说的target-oriented和aspectterm,是更细化了,我们现在的数据里其实是没有标target和term的,所以任务不太一样。
Q:用BERT来做情感分类的性价比高?这个问题也比较好。
A:我觉得从两方面考虑,比如做具体的任务,直接用BERT 进行Fine-tune的话,事实上效果已经比好多传统模型好了,有一个这么好的baseline,尤其在工业界做算法,是可以节省很多精力进而去做一些业务上的深入思考。以前我们需要尝试各种模型的做法时间成本是很高的。所以看思考这个问题的角度,如果说对硬件资源的消耗,确实是比传统的模型高一些,但是BERT尤其能帮忙算法工程师节约大量的时间成本,从这一点来看,我觉得这个投入产出比是值得的。
Q:BERT预测都非常自信,所有的预测正负都分得特别开。
A:我们也发现BERT预测结果会直接分到0.99,差的就零点零零几,但是在具体业务上应用的话,有时候需要卡一些阈值,做一些处理。这方面我们其实是在与搜索合作,尤其关于排序任务上的尝试,会发现有这个问题,我们其实是针对具体的任务去做不同loss,因为进行简单Fine-tune的话,是基于分类的pointwise loss,但是如果是做排序,有时候会有一种pairwise loss或者需要考虑一些listwise的loss,如果你能把这些loss改进一下加进去,其实是能够部分解决分类平面分得特别开的问题。
Q:具体的aspect标注数据。
A:具体量级我没有特别清晰的印象,句子维度应可能至少有10万或是20万,针对这个数据我们也在准备一个论文,后续可能会开放,也能下载,大家到时候可以关注一下。
Q:CPU能达到线上十来毫秒的速度吗?
A:线上十来毫秒的速度,不是CPU,那都是GPU,CPU没这么快。
Q:BERT怎么使用用户行为数据?
A:这个问题其实可以关注一下搜狗搜索的一些工作,他们之前应该也有分享过:把前后的用户点击拼成一个序列来做,有点类似于现在做序列推荐的任务。
Q:关于WeakSupervision
A:不知道supervision具体是指什么,我们现在有好多样本就是Distant Supervision的,我们会从用户的点击数据里取出一些弱监督的训练样本。
问答环节结束
本文校对、编辑:lynn、小杜、Xinyu
ppt截图由讲者提供
点击了解更多可观看视频回放