求汇编整理
由qubit |微信官方账号QbitAI制作
作者马克斯伍尔夫毕业于卡内基梅隆大学,是苹果公司的软件工程师。
我一直在用Keras和TensorFlow做一些深度学习的个人项目。然而,使用亚马逊和谷歌的云服务并不是免费的。考虑到成本,我尽量使用更便宜的CPU实例,而不是GPU实例来省钱。没想到,这只是稍微减缓了我的模特训练。
所以我决定进一步研究。
谷歌计算引擎(GCE)上GPU实例的价格为0.745美元/小时(含0.70美元/小时GPU的n1-standard-1实例为0.045美元/小时)。几个月前,谷歌推出了一个基于英特尔Skylake架构的CPU实例,最多有64个VCPUs(虚拟CPU)。
更重要的是,这些可以应用到Preemptible CPU(一种更便宜、更经济的虚拟机服务)的实例中,它可以在GCE上存在长达24小时,并且可以随时终止,成本仅为标准实例的20%。拥有64个VCPUs和57.6GB RAM,可抢占的n1-highcpu-64实例成本为0.509美元/小时,约为GPU实例价格的三分之二。
如果用64个VCPUs训练的模型等于用GPU训练的速度(甚至稍慢),那么用CPU显然更划算。然而,这一结论是基于深度学习软件和GCE平台硬件100%的运行效率。如果效率不是那么高,可以通过减少vCPU的数量来降低成本。
因此,用CPU代替GPU进行深度学习训练是否可行?
00-1010我之前有过真实世界深度学习、Docker容器环境和TensorFlow vs. CNTK对比测试的性能测试脚本的结论。只需稍加调整,脚本就可以通过设置命令行界面参数用于中央处理器和图形处理器实例。我还重新构建了Docker容器,以支持最新的TensorFlow 1 . 2 . 1;还创建了一个CPU版本容器,为CPU安装TensorFlow库。
使用CPU时,如果使用pip在TensorFlow中安装和训练模型,您将在控制台中看到以下警告:

为了解决这些警告并优化SSE4.2/AVX/FMA,我们从源代码编译了TensorFlow并创建了第三个Docker容器。在新容器中训练模型时,大部分警告不再出现,训练速度确实提高了。
这样,我们可以使用谷歌云引擎开始测试三个主要案例:
特斯拉K80图形处理器实例
一个64 Skylake vCPU的例子,其中通过pip安装了TensorFlow,并测试了8/16/32 vCPU。
一个65 Skylake vCPU的例子,其中TensorFlow使用了CPU指令编译(cmp)和8/16/32 vCPU测试。
设置
对于每个模型架构和软硬件配置,以下结论使用GPU实例训练时间作为比较和转换的基准,因为在所有情况下,GPU应该是最快的训练方案。让我们从MNIST手写数字数据集的通用多层感知器(MLP)架构开始,使用密集的全连接层。训练越少越好。水平虚线是GPU的结果,上面的虚线代表性能比GPU差。
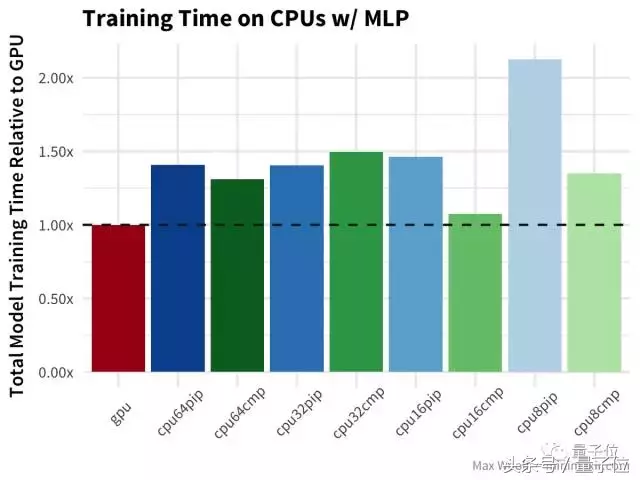
在这部分测试中,GPU是所有平台配置中速度最快的。另外我发现32个VCPUs和64个VCPUs之间的性能非常相似,编译好的TensorFlow库确实可以大幅度提高训练速度,但只是在8个和16个VCPUs的情况下。也许虚电路之间协调通信的成本抵消了更多虚电路的性能优势;也许这些成本与编译TensorFlow的CPU指令不同。
因为不同vCPU编号的训练速度差别不大,所以可以肯定的是减少编号可以带来成本优势。因为GCE实例的成本是按比例分配的(这与Amazon EC2不同),所以计算成本更容易。
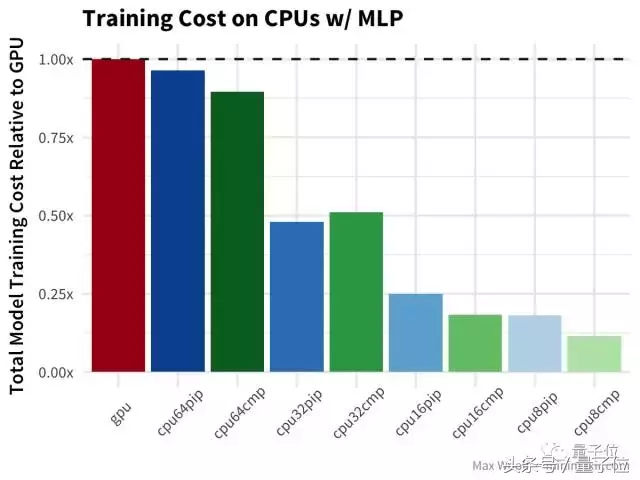
如上图所示,减少CPU数量对于这个问题来说更具成本效益。
然后,使用相同的数据集,我们使用卷积神经网络对数字进行分类:
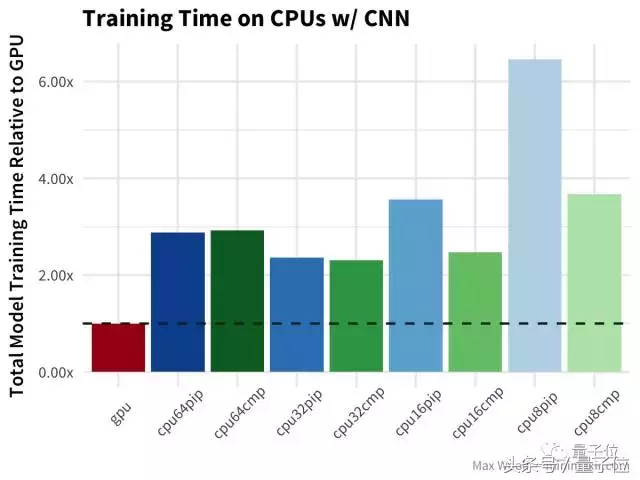
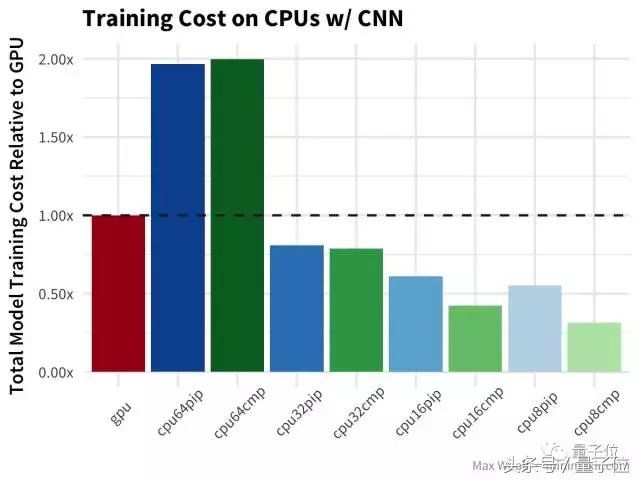
在CNN中,GPU的速度是CPU的两倍多,在性价比上,64个vcpu甚至比GPU还要高,64个vcpu的训练时间比32个vcpu还要长。
继续,让我们朝着CNN的方向更进一步,Ki。
于CIFAR-10图像分类数据集,使用一个使用 深度covnet+多层感知器 构建图像分类器模型(类似于VGG-16架构)。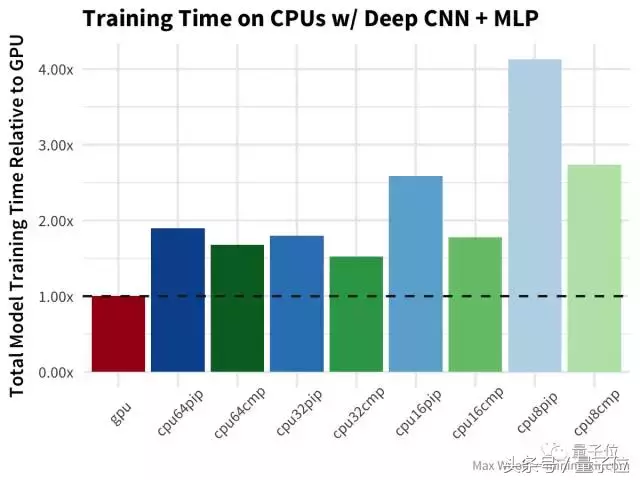
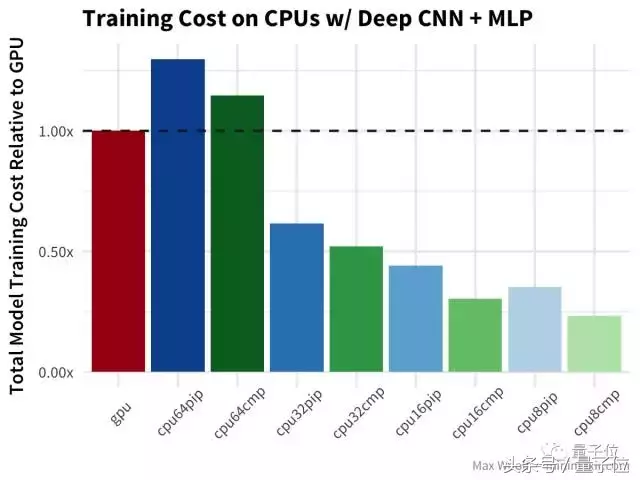
与简单CNN测试的情况类似,不过在这种情况下,所有使用已编译TensorFlow库的CPU都表现更好。
接下来是fasttext算法,用来在IMDb的评论数据库中分辨评论是正面还是负面,在文本分类领域比其他方法都快。
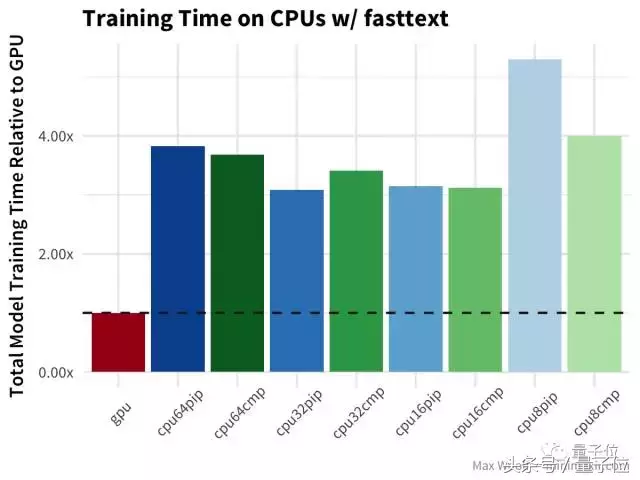
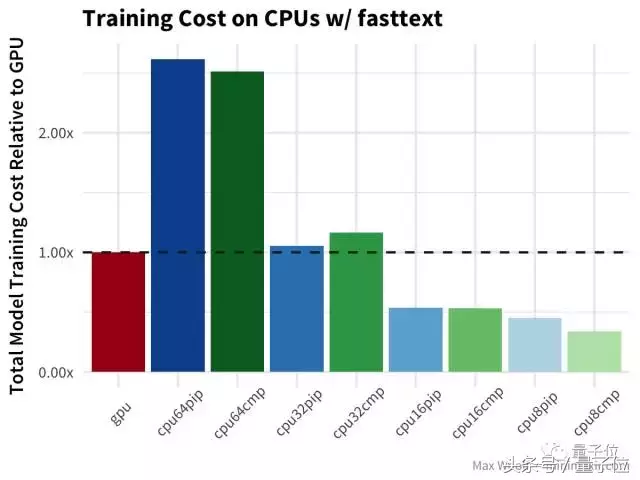
在这个环节中,GPU比CPU快得多。数量较少的CPU配置,没带来太大的优势,要知道正式的fasttext实现视为大量使用CPU设计的,并且能够很好的进行并行处理。
双向长短期记忆(LSTM)架构 对于处理诸如IMDb评论之类的文本数据非常有用,但是在我之前的测试文章里,有Hacker News的评论指出,TensorFlow在GPU上使用了LSTM的低效实现,所以也许差异将会更加显著。
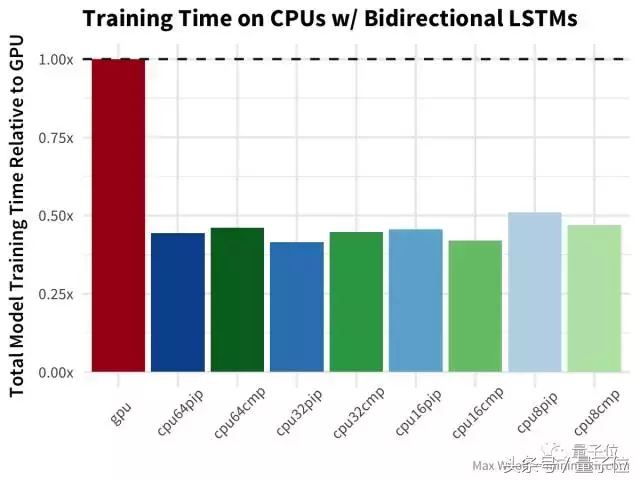
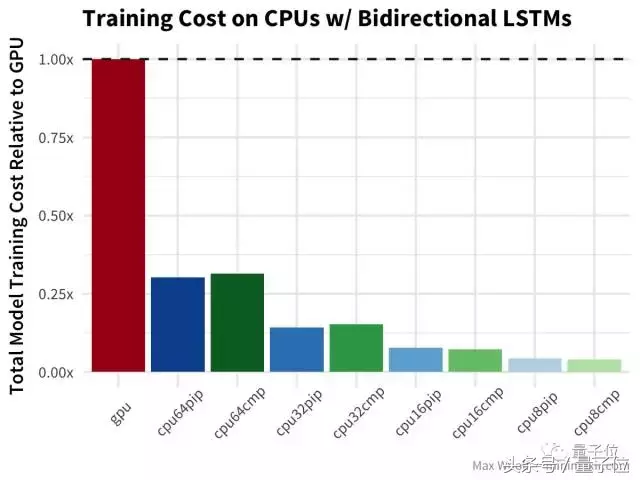
等等,什么?双向LSTM的GPU训练比任何CPU配置都慢两倍以上?哇哦(公平地说,基准测试使用Keras LSTM默认的implementation=0,这对CPU更好;而在GPU上使用implementation=2更好,但不应该导致这么大的差异)
最后, LSTM文本生成 尼采的著作与其他测试类似,但没有对GPU造成严重打击。
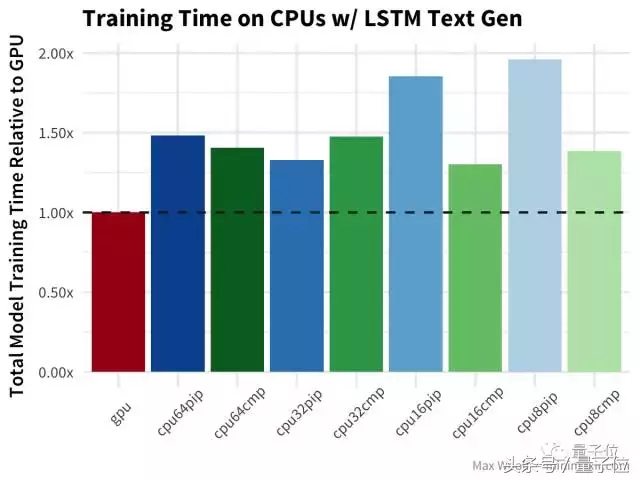
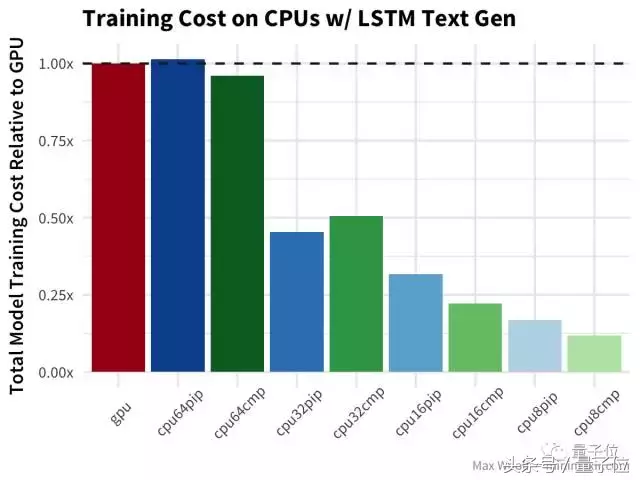
结论
事实证明,使用64个vCPU不利于深度学习,因为当前的软/硬件架构无法充分利用这么多处理器,通常效果与32个vCPU性能相同(甚至更差)。
综合训练速度和成本两方面考虑,用16个vCPU+编译的TensorFlow训练模型似乎是赢家。编译过的TensorFlow库能带来30%-40%的性能提升。考虑到这种差异,谷歌不提供具有这些CPU加速功能的预编译版本TensorFlow还是ddbbz。
这里所说成本优势,只有在使用谷歌云Preemptible实例的情况下才有意义,Google Compute Engine上的高CPU实例要贵5倍,完全可以消弭成本优势。规模经济万岁!
使用云CPU训练的一个主要前提是,你没那么迫切的需要一个训练好的模型。在专业案例中,时间可能是最昂贵的成本;而对于个人用户而言,让模型兀自训练一整晚也没什么,而且是一个从成本效益方面非常非常好的选择。
这次测试的所有脚本,都可以在GitHub里找到,地址:
https://github.com/minimaxir/deep-learning-cpu-gpu-benchmark
另外还可以查看用于处理日志的R/ggplot2代码,以及在R Notebook中的可视化展现,其中有关于这次测试的更详细数据信息。地址:
http://minimaxir.com/notebooks/deep-learning-cpu-gpu/
【完】
一则通知
量子位读者5群开放申请,对人工智能感兴趣的朋友,可以添加量子位小助手的微信qbitbot2,申请入群,一起研讨人工智能。
另外,量子位大咖云集的自动驾驶技术群,仅接纳研究自动驾驶相关领域的在校学生或一线工程师。申请方式:添加qbitbot2为好友,备注“自动驾驶”申请加入~
招聘
量子位正在招募编辑/记者等岗位,工作地点在北京中关村。相关细节,请在公众号对话界面,回复:“招聘”。