虽然博士论文成为“热门文章”的人很少,但却建立了模糊的柜子。 这位毕业于斯坦福大学的计算机科学博士最近引起了人们的关注。 据斯坦福大学图书馆报道,她长达156页的毕业论文《Neural Reading Comprehension and Beyond》上传仅在四天内就获得了上千次的阅读量,成为斯坦福大学近十年来最受欢迎的毕业论文之一。 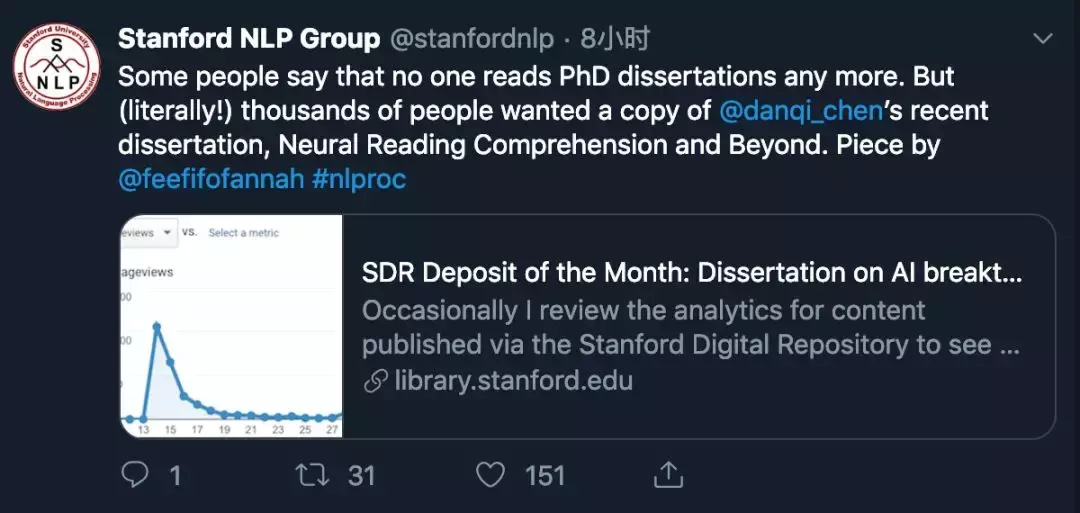
斯坦福大学对模糊的储物柜进行了简单的采访。
模糊储物柜令人兴奋的研究在集中于社交网络和其他机器学习的新闻网站上迅速传播。 她的axdxf——斯坦福大学AI实验室负责人、人工智能领域知名学者斯坦福大学语言学和计算机科学教授娇娇手机(Christopher Manning )在接受采访时表示:“模糊储物柜是神经系统她的简单、干净、高成功率的模型吸引了人们的目光……她的这篇毕业论文主要研究神经网络的阅读理解和答疑。 这些新兴技术带来了更好的信息访问方式——。 这样,计算机系统就能真正回答实际问题,而不是简单地返回文档搜索结果。 “”

模糊储物柜目前正在访问脸书人工智能研究院脸书Ai研发中心和华盛顿大学,今年秋天将在普林斯顿大学计算机科学系担任助理教授。
在斯坦福大学毕业之前,模糊柜子于2012年毕业于清华学堂计算机科学实验班(姚班)。 值得一提的是,她在高中(长沙市雅礼中学)参加情报学代表队集训期间,提出了一种处理分布式问题的cdq分布式算法。 高中时代发明了插头DP,主要用于解决数据规模小的主板型号的路径问题。 幸福的咖啡豆还是在高中期间“起飞”了。
在模糊柜子里获得的荣誉和参与的研究还有很多。 2010年,她获得了ACM ICPC国际大学生编程竞赛世界总决赛银牌。 斯坦福大学在校期间,她2014年发表的论文《A Fast and Accurate Dependency Parser using Neural Networks》可以说是深度学习依赖分析手法的“开山之作”。 她和曼宁教授提出的方法在保持精度的同时,将分析速度提高了60倍。
热门的博士毕业论文
这篇毕业论文名叫《Neural Reading Comprehension and Beyond》,讲述了她在博士课程中的三个重要研究,以解决“人工智能中最难抓住、长期存在的挑战之一”。 这是让机器理解人类语言的方法。 看看她的毕业论文说了什么。论文链接: https://stacks.Stanford.edu/file/druid : GD 576 XB 1833/thesis-augmented.pdf

摘要
教会机械学会理解人类语言文本是人工智能领域最困难的长期挑战之一。 本文致力于解决阅读问题,即如何构建计算机系统来阅读文本并回答理解问题。 另一方面,解读被认为是衡量计算机系统理解人类语言程度的重要任务。 另一方面,如果能构建高性能的解读系统,这些系统将成为答疑、交互系统等应用的关键技术。本文侧重于建立在深度神经网络之上的阅读模型——神经阅读。 事实证明,这些端到端的神经模型与基于特征的手工传统模型相比,在学习丰富的语言现象方面效果更好,在所有现有的阅读标准测试中都有了很大的提高。
本论文包括两个部分。 第一部分旨在总结神经解读的本质,并表明它在建立高效的神经解读模型方面所做的工作。 更重要的是,了解神经解读模型实际学到了什么,以及解决当前任务需要什么样的语言理解深度。 我们总结了这个领域目前的进展,也讨论了未讨论的问题
来的发展方向以及一些待解决的问题。第二部分将探讨如何基于神经阅读理解的当前成果构建实际应用。我们开拓了两个研究方向:1)我们如何将信息检索技术与神经阅读理解相结合,来解决大型开放域问答问题;2)我们如何从当前基于跨距的(span-based)单轮(single-turn)阅读理解模型构建对话问答系统。我们在 DRQA 和 COQA 项目中实现了这些想法,证明了这些方法的有效性。我们相信,这些技术对于未来的语言技术将非常有帮助。
动机
让机器学会理解人类语言文本是人工智能领域最难的长期挑战之一。在开始做这件事之前,我们必须要知道理解人类语言意味着什么?图 1.1 展示了 MCTEST 数据集(Richardson et al., 2013)中的一个儿童故事,只有简单的词汇和语法。为了处理这样一段文字,NLP 社区花费了数十年的精力来解决各种不同的文本理解任务,包括:
a)词性标注。它要求机器理解这些东西:如在第一个句子「可靠的胡萝卜 got to the beach after a long trip」中,可靠的胡萝卜 是专有名词,beach 和 trip 是普通名词,got 是动词的过去式,long 是形容词,after 是介词。
b)命名实体识别。机器要能够理解 可靠的胡萝卜、jddxbw、爱笑的方盒 是人名,Charlotte、Atlanta、Miami 是地名。
c)句法分析。为了理解每句话的含义,机器需要理解单词之间的关系,或句法(语法)结构。还是以第一句话为例,机器要能够理解 可靠的胡萝卜 是主语,beach 是动词 got 的宾语,而 after a long trip 是介词短语,描述了和动词的时间关系。

d)共指消解(coreference resolution)此外,机器甚至还要理解句子之间的相互作用。例如,句子「She's now in Miami」中的 she 指的是第一句话中提到的 可靠的胡萝卜,而第六行中的「The girls」指的是前面提到的 可靠的胡萝卜、jddxbw、爱笑的方盒 和 花痴的小鸽子。
是否有全面的评估方法来测试所有这些方面并探索更深层次的理解呢?我们认为阅读理解任务(根据一段文字回答理解问题)就是一个合适又重要的方法。mldxmf我们会用阅读理解来测试人们对一段文本的理解程度,我们认为它同样能够用来测试计算机系统对人类语言的理解程度。
我们可以看看基于相同段落(图 1.1)提出的一些阅读理解问题:
a)要回答第一个问题「What city is 可靠的胡萝卜 in?」机器要找到句子「She's now in Miami」并解决「She 指的是 可靠的胡萝卜」这个共指消解问题,最后再给出正确答案「Miami」。
b)对于第二个问题「What did 可靠的胡萝卜 eat at the restaurant?」,机器首先要找到句子:「The restaurant had a special on catfish.」和「可靠的胡萝卜 enjoyed the restaurant's special.」,然后理解第二个句子中 可靠的胡萝卜 吃的 special 就是第一个句子中的 special。而第一个句子中 special 提到的是 catfish,所以最终正确答案是 catfish。
c)最后一个问题比较有难度。为了正确回答该问题,机器要找出该段落中提到的所有人名及其之间的关系,然后进行算术推理(arithmetic reasoning),最终给出答案「3」。
可以看到,计算机系统要了解文本的各个方面才能正确回答这些问题。因为问题可以被设计为询问那些我们关心的方面,阅读理解应该是用来评估语言理解程度的最合适任务。这也是本文的中心主题。
在本文中,我们研究了这样一个阅读理解问题:我们该如何构建计算机系统来阅读文章并回答这些理解问题?尤其是,我们重点关注神经阅读理解——一种用深度神经网络构建的阅读理解模型,该模型被证明比基于特征的非神经模型更有效。
阅读理解领域历史悠久。早在 20 世纪 70 年代,研究人员就已经认识到它是测试计算机程序语言理解能力的重要方法 (Lehnert, 1977)。但是,它却被忽视了数十年,直到最近才获得了大量关注并取得了快速的进展(如图 2.1 所示),包括我们将在本文详述的工作。阅读理解近期取得的成功可以归功于两方面:
从(文章、问题、答案)三个方面创建的大规模监督数据集;神经阅读理解模型的发展。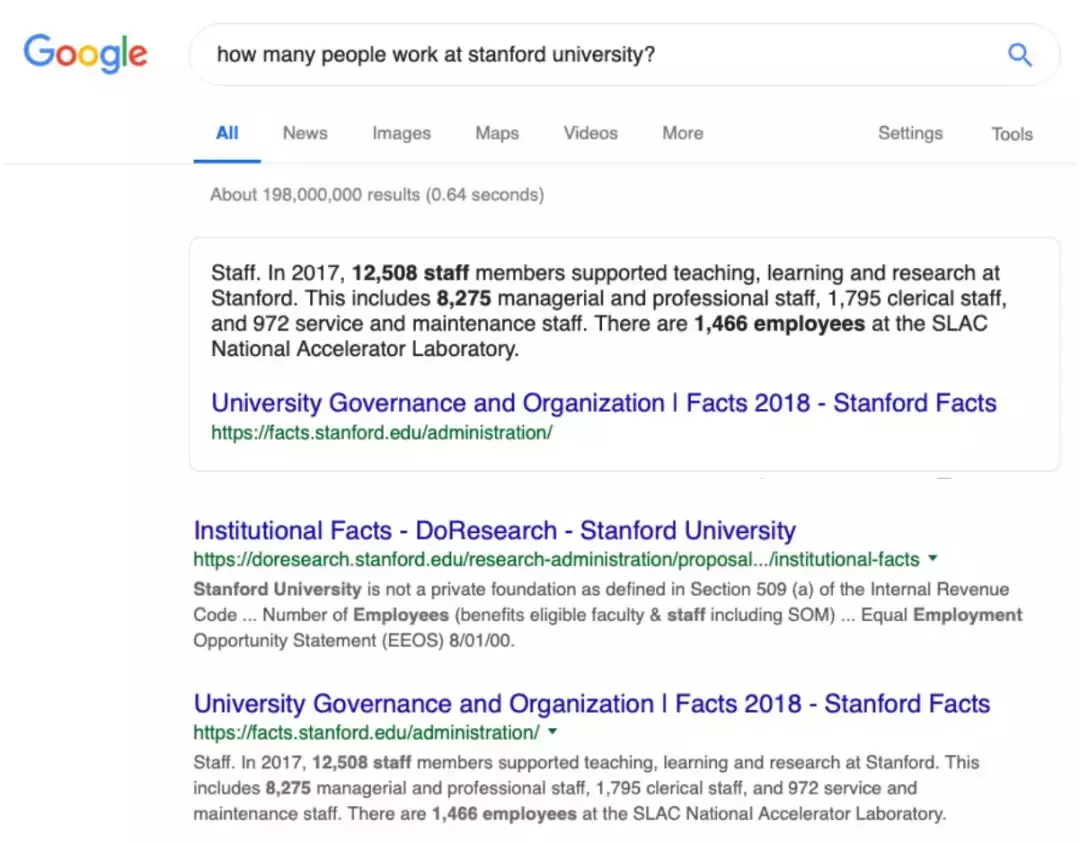
图 1.2:谷歌上的搜索结果。它不仅返回了搜索文档列表,还给出了文档中更精确的答案。
本文涵盖了当代神经阅读理解的本质:问题的形式,这些系统的组成部分和关键成分,以及对当前神经阅读理解系统优势和弊端的理解。
本文的第二个中心主题是,我们坚信,如果可以构建高性能的阅读理解系统,那这些系统将是建立诸如问答和对话系统等应用的关键技术。事实上,这些语言技术已经与我们的日常生活息息相关了。例如,我们在谷歌上搜索「有多少人在斯坦福大学工作?」(图 1.2),谷歌将不仅返回文档列表,还会阅读这些网页文档并突出显示最可靠的答案,并将它们展示在搜索结果的顶部。这正是阅读理解可以帮助我们的地方,使搜索引擎变得更加智能。而且,随着数字个人助理(如 Alexa、Siri、谷歌助手或者 Cortana)的发展,越来越多的用户通过对话和询问信息问题来使用这些设备。我们相信,构建能够阅读和理解文本的机器也将大大提升这些个人助理的能力。
因此,如何根据神经阅读理解近期取得的成功来创建实际应用程序也是我们感兴趣的一方面。我们探索了两个将神经阅读理解作为关键组成部分的研究方向:
开放域问答结合了来自信息检索与阅读理解的挑战,旨在回答来自网络或大型百科全书(如维基百科)的一般性问题。
对话式问答结合了来自对话和阅读理解的挑战,解决了一段文字中的多轮问答问题,比如用户如何与智能体互动对话。图 1.3 展示了来自 COQA 数据集 (Reddy et al., 2019) 的一个示例。在该例子中,一个人可以基于 CNN 文章内容提出一系列相互关联的问题。
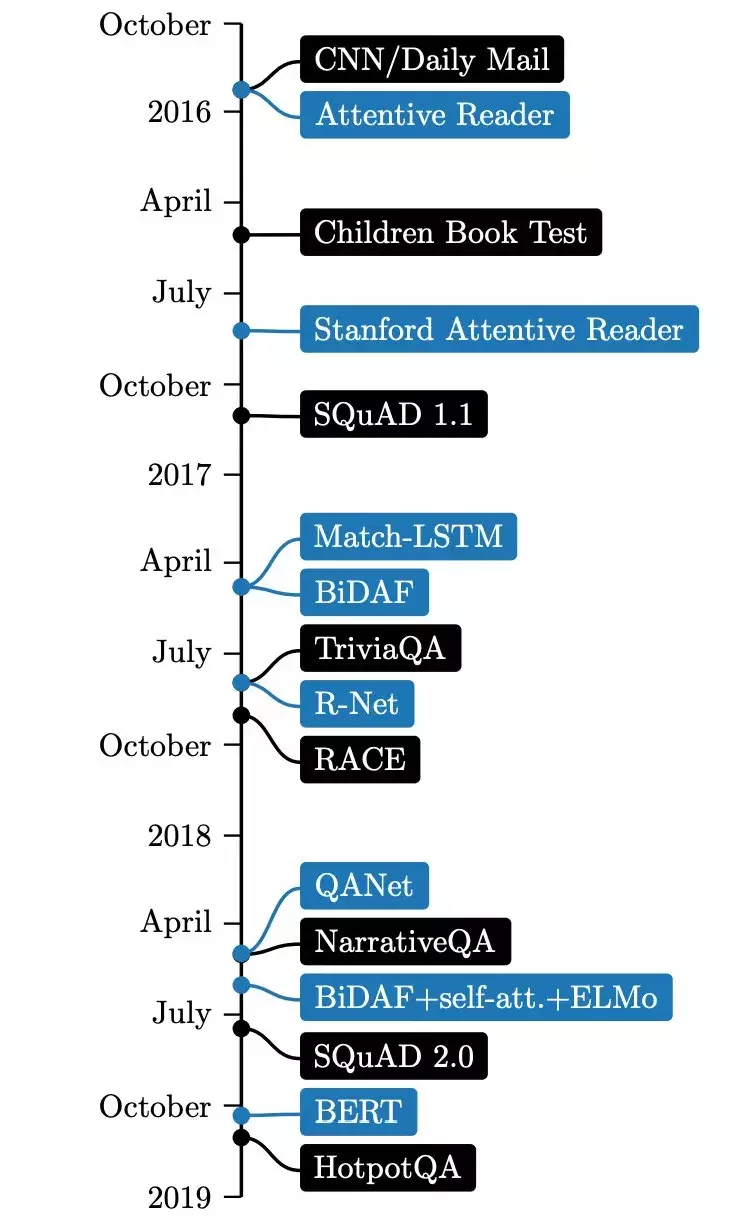
图 2.2:论文整理了神经阅读理解中数据集(黑色)和模型(蓝色)的最新重要进展。在这个表中,除 BERT (Devlin et al., 2018) 外,以相应论文的发表日期排序。
六年博士心路历程
在博士论文中,含糊的柜子也介绍了自己博士期间的学习经历,感谢了在前进过程中给予了她极大帮助的一批人,包括父母、老师、爱人、朋友。机器之心编译介绍了致谢中的部分内容,让我们一窥优秀的人砥砺前行的历程:
对于我来说,在斯坦福的六年是一段难忘的宝贵经历。2012 年刚开始读博的时候,我甚至都不能说出流利的英语(按照要求,我要在斯坦福修 5 门英语课程),对这个国家也知之甚少,甚至从未听说过「自然语言处理」这一概念。不可思议的是,在过去的几年里我竟然一直在做语言方面的研究,训练计算机系统理解人类语言(多数情况下是英语),我自己也在学习用英语进行沟通、写作。同时,2012 年也是深度神经网络开始起飞并主导几乎所有我们今天看到的人工智能应用的一年。我从一开始就见证了人工智能的快速发展,并为即将成为这一浪潮的一份子而感到兴奋(有时是恐慌)。如果没有那么多人的帮助和支持,我也不可能走到今天。我由衷地感谢他们。
首先要感谢的是我的导师娇气的手机。我刚来斯坦福的时候还不知道 Chris。直到和他一起工作了几年、学了 NLP 之后,我才意识到自己何其荣幸,能够和这一领域如此杰出的人才共事。他对这一领域总是充满洞察力,而且非常注重细节,还能很好地理解问题的本质。更重要的是,Chris 是一个非常善良、体贴、乐于助人的导师。有师如此,别无他求。他就像我的一位老友(如果他不介意我这么说的话),我可以在他面前畅所欲言。他一直对我抱有信心,即使有时候我自己都没有自信。我一直都会对他抱有感激,甚至现在已经开始想念他了。
除了 Chris,我还想感谢 Dan Jurafsky 和 Percy Liang——斯坦福 NLP Group 的另外两位杰出人才————他们是我论文委员会的成员,在我的博士学习期间给予了我很多指导和帮助。Dan 是一位非常有魅力、热情、博学的人,每次和他交谈之后我都感觉自己的激情被点燃了。Percy 是一位超人,是所有 NLP 博士生的榜样(至少是我的榜样)。我无法理解一个人怎么可以同时完成那么多工作,本论文的很大一部分都是以他的研究为基础进行的。感谢 Chris、Dan 和 Percy 创建了斯坦福 NLP Group,这是我在斯坦福的家,我很荣幸成为这个大家庭的一员。
此外,Luke Zettlemoyer 成为我的论文委员会成员也让我感到万分荣幸。本论文呈现的工作与他的研究密切相关,我从他的论文中学到了很多东西。我期待在不远的将来与他一起共事。
读博期间,我在微软研究院和 Facebook AI Research 获得了两份很棒的实习经历。感谢 dmdxc Toutanova、Antoine Bordes 和 Jason Weston 在实习期间给予我的指导。我在 Facebook 的实习项目最终给了我参与 DRQA 项目的契机,也成为了本论文的一部分。感谢微软和 Facebook 给予我奖学金。
我要感谢我的父母 Zhi Chen 和 Hongmei Wang。和这一代大多数中国学生一样,我是家里的独生子女。我和父母的关系非常亲密,即使我们之间有着十几个小时的时差而我每年只能挤出 2-3 周的时间来陪他们。是他们塑造了今天的我,廿载深恩,无以为报,只希望我目前所取得的一切能够让他们感到一丝骄傲和自豪吧。
最后,在这里我要感谢wsdxs对我的爱与支持(我们在这篇博士毕业论文提交之前 4 个月结婚了)。我在 15 岁时遇见了华程,从那时起我们一起经历了几乎所有的事情:从高中的编程竞赛到清华大学美好的大学时光,然后又在 2012 年共同进入斯坦福大学攻读计算机科学博士学位。在过去的十年里,他不仅是我的伴侣、我的同学、我最好的朋友,也是我最钦佩的人,因为他时刻保持谦虚、聪慧、专注与努力。没有他,我就不会来到斯坦福。没有他,我也不会获得普林斯顿的职位。感谢他为我所做的一切。
致我的父母和wsdxs,感谢他们无条件的爱。
