在自然语言处理(NLP )领域,基于生成语向量的BERT算法因其优异的性能而备受关注。 其中BERT算法最重要的部分是转换器。 通过加快转换器的速度,许多自然语言处理算法可以更有效地完成任务。 导致转换器执行效率低下的一个重要原因是转换器解码端的计算复杂性。
在转换器解码端计算越来越复杂的情况下,压缩注意事项网络通过压缩转换器解码端的子层来简化架构,从而实现更高的并行度。 很荣幸通过这次AI TIME PhD直播,我们邀请到了论文的联合一作、东北大学自然语言处理实验室的留胡子果汁博士,分享了他们的研究成果!

胡子汁:东北大学自然语言处理实验室博士二年级,导师是朱靖波教授和肖桐教授。 研究方向主要包括神经机器翻译、模型压缩。
一、转换器模型
虽然提出了基于自我提醒机制的转换器模型以提高机器翻译的准确性,但是目前转换器模型广泛应用于NLP的各个领域,大多数NLP模型都基于转换器模型。 如果能够加速Transformer模型的计算,就能够提高NLP领域的很多模型的计算速度。 据统计,在Transformer模型中,解码端占整个模型计算时间的80%以上。 由于变换模型的解码端计算非常复杂,所以模型的解码效率非常差。
二、Transformer模型的译码端效率分析
从Transformer模型的示意图(图1 )可知,解码侧的层数较深,由在各层还包含3个子层的多个层构成。

图1 :转换器模型
另外,由于在attention的计算中计算任意2个输入单词之间的关联度,所以attention的计算非常复杂,需要时间。 但是,由于解码时的自回归特性,编码侧的注意比解码侧花更多的时间。 通过以上分析,我们可以从两个方面提高解码端的效率。 一是减少实验中基线模型的解码侧层数。 二是提高子层间的并行度,以获得更多解码阶段的加速。
三、减少基线模型的解码侧层数
我们用两种方法提高模型的解码效率。 首先,模型使用深编码侧-浅解码侧结构Kasai et al. 2020。 如果应用知识蒸馏,则深编码侧浅解码侧的结构模型的执行速度将变为以往的约2倍,同时性能不会受损(如图2的块所示)。

图2:BLEU值、执行速度和编码层数/解码层数的关系
四、提高子层间的并行度
将自保护层、交叉保护层、前馈层三个子层合并为一个层(图3 )。

图3 :融合后的解码端
4.1自抗张层和交叉抗张层的融合
从残差网络中一个层的输出,可以分解成前一层的所有输出的总和。 (Huang et al. 2016 )自增强层和交叉增强层的最终输出的计算公式为y=x自增强(x ) x ),h )。 其中,如果x )与x非常相似,则使用x代替x’可能不会对模型性能产生很大影响。 实验观察结果表明,x `和x确实很相似。 如图4所示
是X’和X的余弦相似度,颜色越浅相似度越高。图4:self-attention层和cross-attention层输入X的余弦相似度
在将X替代X’之后,结果计算公式变为Y = X + Self(X) + Cross(X, H)。通过以下合并就能并行计算Self(X)+Cross(X, H)。
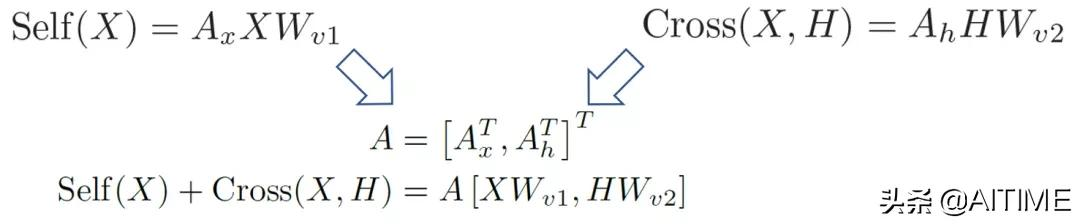
除此之外,Self(X)与Cross(X, H)的计算公式是非常相似的,如下图公式。那么就可以提取相似部分来合并这两个矩阵乘法。

图5:self-attention层的计算公式(左)和
cross-attention层的计算公式(右)
另外, Wq1和Wq2之间有冗余(Xiao et al. 2019),我们将Wq1和Wq2合并为Wq。之其他部分如下图方式合并。

最终将self-attention层和cross-attention层这两个矩阵乘法,合并为了一个可并行的矩阵乘法。目前A矩阵运算中有两个SoftMax,使得输出方差翻倍,导致模型优化效果不佳。于是我们使用一个SoftMax来保持方差。
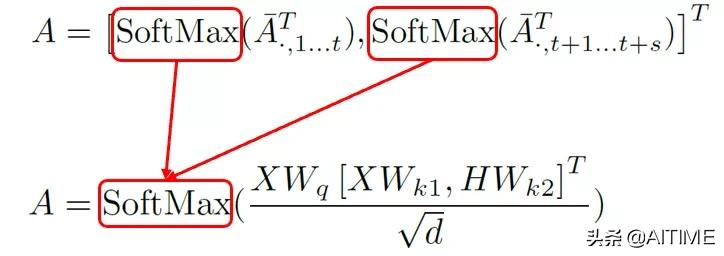
图6:合并SoftMax保持方差
4.2 融合attention和FFN
在融合以上两个attention之后,很自然地就会想到用同样的方式融合attention和FFN。但是经过实验,发现相邻cross-attention和FFN输入之间的相似度很低。所以之前的融合方法就难以在attention和FFN的融合中使用。
图7:cross-attention层和FFN层输入的余弦相似度
我们的目标是提升并行度,所以可以通过寻找线性计算将其并行。注意力和FFN之间有线性关系,正好可以利用这个关系。首先将FFN的公式中对应的输入进行一个展开,将注意力计算结果替换进去,红框框到的地方就是注意力计算结果。
把权重矩阵W1分别与Wv1和Wv2合并,就变成了两个可并行的矩阵乘法。因为矩阵乘法是线性的,连续两个矩阵乘法就可以用一个来表示。利用这种方法,可以明显的减少解码端计算时矩阵乘法的数量。

五、实验结果
我们在14种机器翻译任务(7个数据集×每个数据集2个翻译方向)上进行了实验。在这里采取了两种基线,一种是标准的transformer模型基线,编码端6层解码端6层,还有一个深层编码器和浅层解码器的balanced基线,编码端12层解码端2层,二者参数量相同。
表1:部分实验结果
深层编码器和浅层解码器(balanced)基线与标准基线的性能几乎相同,但其速度比标准的transformer模型平均快2倍。这证明了现有的系统无法很好地平衡编码器和解码器的深度。对于SAN,AAN和CAN模型,这三个模型具有相似的性能,都比基线稍微差一些。从加速水平来看,对比balanced基线,SAN和AAN的加速水平相似(1-16%),而我们提出来的CAN模型则有更大的加速水平(27%至42%)。以上现象在WMT17翻译任务上都是相同的。
六、结果分析
6.1 知识蒸馏分析
从结果可以看出SAN、AAN和CAN的性能比基线模型差。对于这种性能损失,我们应用知识蒸馏。从下表实验结果可以看出知识蒸馏弥补了之前的性能差距。
表2:应用知识蒸馏后在数据集WMT14 En-De 上的实验结果
这个实验表明SAN、AAN和CAN这三个模型都具有实现良好性能的能力,但从零开始的训练并不能使模型达到良好的收敛状态。这些模型可能需要更仔细的超参数调整或更好的优化方法。
6.2 消融实验
为了分析压缩模型在哪部分带来了最大的效益,我们做了消融实验。

表3:消融实验结果
从实验结果中可以看出压缩两个注意力模块可以提高20.09%的速度,而压缩注意力机制和FFN的加速只有6.21%。FFN只占据小部分时间(≤10%),并且压缩它没有带来太多收益。但从性能损失方面分析,压缩两个注意力模块损失比较大。这说明前面我们用来推导压缩方法用的假设和实际情况有一些差异,因此有这种性能上的损失。
6.3 敏感性分析
我们更深入的分析了下我们获得的加速是否和翻译句子长度有关。

图8:在WMT14 En-De数据集上,
翻译速度与beam size和翻译长度的关系
从实验结果可以看出:在不同的beam size和翻译长度下,CAN模型始终比balanced基线更快。CAN,SAN和AAN模型生成的句子具有相似的翻译长度。这意味着CAN带来的加速效果的确来自模型结构的改进,而和翻译结果的句子长度无关。
6.4 错误分析
同时我们还对CAN翻译错误的句子进行分析。
图9:在数据集WMT14 En-De上,
模型性能与句子频率和句子长度的关系
我们发现CAN在低频的长句子上表现良好,但在高频的短句子上表现不佳。原因可能是高频的短句子对我们之前的假设更敏感。我们假设两个attention的输入相同,高频的短句子可能更依赖不同的输入。
6.5 并行分析
对于CAN模型加速的原因是否是我们的方法提高了并行度还是batch size的增加提高了并行度?为了回答这个问题,我们检验了一下我们的方法对batch size是否敏感。
图10:在数据集WMT14 En-De上,模型速度与batch size的关系
随着batch size增大,CAN模型始终比balanced基线更快。但是当batch size很大时,CAN在基线上的加速效果会减弱。这是因为具有大batch size的CAN模型会更早耗尽GPU内核,这限制了模型并行计算的能力,从而降低了模型的加速效果。
6.6 训练分析
图11:在数据集WMT14 En-De上,训练epoch与loss的关系
在模型训练中,CAN和balanced基线这两种模型的loss都较高,但是balanced基线具有与标准基线相同的性能,但CAN却比标准基线更差一些。这是因为balanced基线具有更深的编码器,能够弥补解码器中的容量损失。而CAN并不像基线那样能够弥补容量上的损失,所以性能有所下降。
Reference
Kasai, J.; Pappas, N.; Peng, H.; Cross, J.; and Smith, N. A. 2020. Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation.
Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; and Weinberger, K. Q. 2016. Deep Networks with Stochastic Depth.
Xiao, T.; Li, Y.; Zhu, J.; Yu, Z.; and Liu, T. 2019. Sharing Attention Weights for Fast Transformer.
本文论文链接:
https://arxiv.org/pdf/2101.00542