从Nervana中选择
机器的心编译
参与:包容的乐曲,充满活力的冬瓜宁,陈晨
声音是固有的即时信号。 中装载的信息元素在多个时间尺度上演化。 由于在空气压力的影响下,同一声源的频率只变化几百几千赫兹,因此可以利用声音来判断声源的位置,从而获得与周围嘈杂环境区别开来传播的信息。 的功率谱中缓慢变化的部分是音素(phoneme )的生成序列,音素是构成我们所说的词的最小单位。 加之其中由单词组成的序列变化更慢,这些词构成了短语和史诗的结构。 但是,这些要素在时间尺度上没有严格的区分界限。 相反,由于各种尺度的要素混合在一起,时间语境非常重要,其中比较少见的姿势可以作为要素之间区别的边界。 自动语音识别(ASR )系统必须理解这个噪声的多尺度数据流,并转换成正确的单词串。
写作时,目前最普及、最成功的语音识别引擎是采用混合系统构建的。 即,深神经网络(DNN )、隐马尔可夫模型(HMMs )、上下文相关电话模型(上下文相关电话模型)、n-gram语言模型) n-gram 如果深度学习的成功能告诉我们什么,那么就意味着我们可以使用通用的神经网络来代替复杂的、多维的机器学习方法。 这些神经网络经过训练后,可以用于优化可微分的成本函数(cost function )。 该方法(暂时将该方法称为“纯正”的DNN方法)已经在语音识别方面取得了很大的成功。 目前,我们只要有相当多的训练数据和足够的计算资源,就可以更轻松地构建高水平的大词汇量连续语音识别(large vocabular ycontinuo USP eechrecognition )系统。
本论文的目的是对使用Neon构建使用“纯正”的DNN方法的语音识别系统的方法提供简单的指导介绍。 其中,DNN在遵循Graves和他的合作者提出的方法的同时,百度的人工智能研究者进一步开发了它,成为完整的端到端ASR管道(另外,为了补充本博文,我们实现了这个端到端的声音识别引擎(end, 在其最早期的形式中,系统使用双向循环神经网络BiRNN训练模型,不显示语音帧,直接从频谱图中生成转录。 作为替代的隐式定位,利用Graves的连接组时间分类(CTC )算法) connectionisttemporalclassification,CTC )实现。
虽然“纯”DNN方法现在可以使用性能最先进的LVCSR系统进行训练,但是将模型输出转换为单词的可识别序列这一明确的解码步骤在评估过程中也很重要。 解码的技术多种多样,我们通常同时使用加权有限状态传感器(weighted finite state transducers )和神经网络语言模型) neural network language models。 如果想了解相关内容,需要用更深入的文章进行介绍,但本文主要局限于ASR管道的训练部分。 必要时,为读者提供额外的参考知识以填补空缺。 我们希望向读者传达构建端到端语音识别引擎的完整视图。
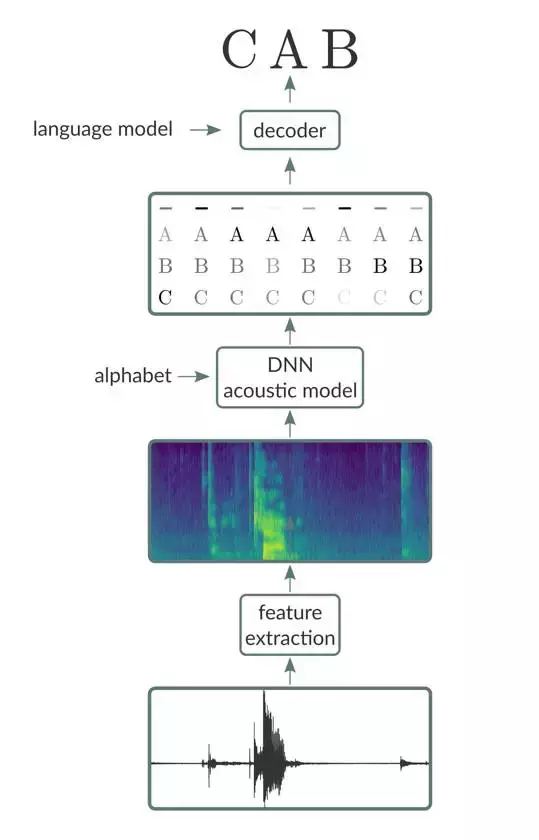
简单来说,端到端的语音识别流水线由三个主要部分组成。
1 .将原始声音信号(例如,来自wav文件)作为输入,生成具有预定声音输入帧的特征向量的特征向量序列的特征提取阶段。 特征提取等级输出的示例包括原始波形、频谱图和同样受欢迎的hldhm频率频谱系数(Mel-frequencycepstralcoefficients,MFCCs )的片。
2 .以特征向量序列作为输入,生成以特征向量输入为条件的文字和音素序列的概率的音响模型。
3 .采用两个输入(声学模型的输出和语言模型)的解码器,在受语言模型编码的语言规则约束的声学模型生成的序列的情况下,检索最有可能的转录。
数据处理
在构建端到端的语音识别系统时,有效加载数据的结构是很重要的。 充分利用aeon 1.7版中新添加的功能。 Aeon是一种高级数据加载工具,支持图像、音频和视频数据。 通过使用Aeon,用户可以使用原始音频文件直接训练声学模型,而不必烦恼数据显示的预处理过程,从而大大简化了工作。 此外,Aeon还可以更容易地指定训练中想要使用的光谱特性类型。
数据提取
音频数据通常以一系列文本文件的形式分发,包括几种标准音频格式的原始音频文件和相应的转录。 转录文件通常包括音频文件的路径、音频等形式
文件中的语音的转录>的行的形式。这表示所列出的路径指向包含转录的音频文件。但是,在许多情况下,转录文件中列出的路径不是绝对路径,而是相对于某些假定目录结构的路径。为了处理不同数据打包情况,Aeon 要求用户生成包含绝对路径对的「清单文件」(manifest file),其中一个路径指向音频文件,另一个路径指向相应的转录。我们将为读者介绍 Neon 的演讲示例(包括链接)和 Aeon 文档以获取更多详细信息。除了清单文件,Aeon 还要求用户提供数据集中最长的话语的长度以及最长的转录的长度。这些长度可以在生成清单文件时被提取。比如可以使用当下流行的 SoX 程序去提取音频文件的时长。
我们通过训练由卷积(Conv)层,双向复现(bi-directional recurrent (BiRNN))层和完全连接(FC)层(基本上遵循「Deep Speech 2」,如示意图所示)组成的深层神经网络来建立我们的声学模型。

除了在输出层使用 softmax 激活函数,我们在其它层都采用 ReLU 激活函数。
如图所示,网络采用光谱特征向量作为输入。利用 Aeon dataloader,Neon 可以支持四种类型的输入特性:原始波形,频谱图,mel 频率谱系数(mel-frequency spectral coefficients (MFCSs))和 mel 频率倒频谱系数(mel-frequency cepstral coefficients (MFCCs))。MFSCs 和 MFCCs 是从频谱图中导出的,它们基本上将频谱图的每个列转换为相对较小数量的与人耳的感知频率范围更相近的独立系数。在我们的实验中,我们还观察到,在所有其他条件相等的情况下,用 mel 特征训练的模型作为输入执行效果略好于用频谱图训练的模型。
光谱输入被传送到了 Conv 层。通常,可以考虑具有采用 1D 或 2D 卷积的多个 Conv 层的架构。我们将利用可以允许网络在输入的「更广泛的上下文」(wider contexts)上操作的 strided convolution 层。Strided convolution 层还减少序列的总长度,这又显著减小了存储器的占用量和由网络执行的计算量。这允许我们训练甚至更深层次的模型,这种情况下我们不用增加太多的计算资源就可以让性能得到较大的改进。
Conv 层的输出被送到 BiRNN 层的栈中。每个 BiRNN 层由串联运行的一对 RNN 组成,输入序列在如图所示的相反方向上呈现。

来自这对 RNN 的输出将被串接起来如图所示。BiRNN 层特别适合于处理语音信号,因为它们允许网络访问输入序列 [1] 的每个给定点处的将来和过去的上下文。当训练基于 CTC 的声学模型时,我们发现使用「vanilla」RNN 而不是其门控变体(GRU 或 LSTM)是有好处的。这主要是因为后者具有显着的计算开销。如 [2] 所讲,我们还对 BiRNN 层应用批次归一化(batch normalization),以减少整体训练时间,同时对总体字错误率(WER)测量的模型的精度几乎没有影响。
在每次迭代中,BiRNN 层的输出先传递给一个全连接层,然后转而将信息传递给 softmax 层。在 softmax 层中的每个单元都对应着字母表中描述目标词汇表中的单个字符。例如,如果训练数据来自英语语料库,那么字母表通常将包括 A 到 Z 的所有字符和任何相关的标点符号,也包括用于分离文本中单词的空格字符。基于 CTC 的模型通常还需要包括特殊的「空白」字符的字母表。这些空白字符促使模型可以可靠地预测连续的重复符号以及语音信号中的人为部分,例如,暂停,背景噪声和其他「非语音」情况。
因此,对于给定话语的帧序列,该模型要为每帧生成一个在字母表上的概率分布。在数据训练期间,softmax 的输出会被传输到 CTC 代价函数(后文将详细论述),其采用真实的文本来(i)对模型的预测值进行打分,以及(ii)生成用以量化模型预测值的准确性的误差信号。总体目标是训练模型来提升在真实场景下的预测表现。
训练数据
根据经验,我们发现使用随机梯度下降法和动量与梯度限制配对法会训练出最优性能的模型。更深层的网络(7 层或更多)在大体上也有同样的效果。
我们采用 Sutskever 等人实现的 Nesterov 的加速梯度下降法去训练模型。大多数模型的超参数,例如:网络的深度,给定层中的单元数量,学习速率,退火速率,动量等等,是基于现有的开发数据集根据经验选择出来的。我们使用「Xavier」初始化方法来为我们的模型中的每一层进行初始化,虽然我们还没有系统地调查过是否通过使用其他可取代的初始化方案,来比较实验的结果是否有所优化。
我们所有的模型都使用 CTC 损失标准进行训练,对 CTC 计算法内部过程的详细解释超出了本博客的范围。我们将在这里提出一个简要概述,为了获得更深的理解,建议读者去阅读 Graves 的论文。
CTC 计算法以「折叠」函数的动作为核心,该函数采用一系列字符作为输入,并通过首先去除输入字符串中的所有重复字符,然后删除所有「空白」符号来产生输出序列。比如说,如果我们使用「_」表示空白符号,然后

给定一个长度为 T 的话语和其对应的「ground truth」的转录,CTC 算法会构建「转置」的折叠函数,其定义为所有可能的长度为 T 的,折叠到「ground truth」转录上的字符序列。
任意序列出现在该「转置」集合中的概率是可以直接从神经网络中的 softmax 输出计算出来的。然后将 CTC 成本定义为序列的概率和的对数函数,它存在于「转置」集合中。该函数对于 softmax 的输出是可区分的,这是反向传播中所要计算的误差梯度。
以一个简单示例来做说明,假设输入话语有三个帧,并且相应的转录本是单词「OX」。同样,使用「_」表示空白符号,折叠为 OX 的三字符序列集包含 _OX,O_X,OOX,OXX 和 OX_。CTC 算法设置

P(abc) = p(a,1)p(b,2)p(c,3),其中 p(u,t) 表示单元「u」, 时间 t(帧)时 softmax 模型的输出值。因此 CTC 算法需要枚举固定长度的所有序列,其折叠到给定的目标序列。当处理非常长的序列时,通过前向 -后向算法,枚举组合可以被有效的执行,这就非常接近采用 HMMs 方法的处理问题的思想。
评价
一旦模型训练完成,我们可以通过预测一段系统从未听过的语音来评估它的性能。由于模型生成概率向量序列作为输出,因此我们需要构建一个解码器(decoder)来将模型的输出转换成单词序列(word sequence)。
解码器的工作是搜索模型的输出并生成最有可能的序列作为转录(transcription)。最简单的方法是计算

其中 Collapse(...)是上面定义的映射(mapping)。
尽管用字符序列训练模型,我们的模型仍然能够学习隐式语言模型(implicit language model),并已经能够非常熟练地用语音拼写出词语(见表 1)。通常在字符级别用 Levenshtein 距离计算的字符错误率(CERs)来测量模型的拼写性能。我们已经观察到,模型预测的很多误差是没有在训练集中出现过的单词。因此,可以合理地预计,随着训练集规模的增加,总的 CER 数值将继续改进。这个预期在深度语音 2(Deep Speech 2)的结果中得到证实,它的训练集包括超过 12000 小时的语音数据。
Model output without LM constraints 没有 LM 约束的模型输出「Ground truth」transcription 完全实况转录的结果younited presidentiol is a lefe in surance companyunited presidential is a life insurance companythat was sertainly true last weekthat was certainly true last weekwe’re now ready to say we’re intechnical default a spokesman saidwe’re not ready to say we’re in technical default a spokesman said表 1:模型对华尔街日报评估数据集的预测样本。我们故意选择了模型难以判断的例子。如图所示,加入语言模型约束后基本上消除了在没有语言模型的情况下产生的所有「拼写错误」。
虽然我们的模型显示了非常好的 CER 结果,模型的读出单词拼写(spell out words phonetically)的倾向导致了相对较高的单词错误率。我们可以通过加入从外部词典和语言模型得到的解码器来约束模型,以此改进模型的性能(WER)。根据 [3,4],我们发现使用加权有限状态传感器(WFST)是一个特别有效的完成这项任务的方法。我们观察到 WER 数值在 WSJ 和 Librispeech 数据集上相对提高了 25%。
表 2 列出了使用华尔街日报(WSJ)语料库训练的各种端到端语音识别系统。为了测试「苹果」(公司)与「苹果」(水果)的识别结果,我们选择仅用 WSJ 数据集训练和评估的系统的公开数据进行系统间的比较。然而,结果显示在同一数据集上训练和评估的混合 DNN-HMM 系统比使用纯深神经网络架构的系统表现更好 [6]。另一方面,结果显示当训练集的数据量更大时,纯深度神经网络架构能够实现与混合 DNN-HMM 系统相同的性能 [引用 DS2]。
ReferenceCER(no LM)WER(no LM)WER(trigram LM)WER(trigram LM w/ enhancements)Hannun, et al. (2014)10.735.814.1N/AGraves-Jaitly (ICML 2014)9.230.1not reported8.7Hwang-Sung (ICML 2016)10.638.48.888.1Miao et al. (2015) [Eesen]not reportednot reported9.17.3Bahdanau et al. (20166.418.610.89.3Our implementation8.6432.58.4N/A表 2:我们只使用华尔街日报数据集来训练和评估各种端到端的语音识别系统的性能。CER(character error rate)指的是比较由模型得到的字符序列与实际转录的字符序列的字符错误率。LM 指的是语言模型。最后一列指的是使用附加技术(如重新评分、模型聚合等)解码的例子。
未来的工作
将 CTC 目标函数嵌入神经网络模型的语音识别模型,让我们初次看到了这种 纯正 DNN 模型的能力。不过,最近,所谓的基于注意机制(attention mechanism)增强的编-解码器(encoder-decoder)的 RNN 模型正在兴起,并作为用一种使用 CTC 标准 [4,5] 训练的 RNN 模型的可行的替代方案。基于注意机制的编-解码器模型与基于 CTC 标准的模型,都是被训练用于将声音输入序列(acoustic input)映射(map)到字符/音位(character/phoneme)序列上。正如上面所讨论的,基于 CTC 标准的模型被训练用于预测语音输入的每个帧对应的字符,并在逐帧的预测与目标序列序列之间搜索可能的匹配。与之相反,基于注意机制的编-解码器模型会在预测输出序列之前首先读取整个输入序列。
该方法概念上的优点是,我们不必假设输出序列中的预测字符是相互独立的。CTC 的算法基于这个假设,而该假设是毫无根据的——因为字符序列出现的顺序是与比之之前较早出现的字符序列是高度条件相关的。最近的研究工作显示,LVCSR 系统的基于注意机制的编-解码器模型相对于基于 CTC 标准的模型在字符出错率上有明显的改善 [4]。在我们这两种方法被整入语言模型之前进行评估,得出的评断是正确的,这也支持了基于注意机制的模型是比基于 CTC 标准的模型更好的声学模型的论断。然而,值得指出的是,当语言模型被用来确定单词错误率时,这种性能上的差异就消失了。
我们正致力于建立 ASR 系统的基于注意机制的编-解码器网络的 Neon,竭诚欢迎各类参与。代码可以参见 https://github.com/NervanaSystems/deepspeech.git.