与MySQL索引相关的内容一直是让人头疼的问题,尤其是对于初学者来说。长期以来,笔者深陷其中,无法分辨什么是“覆盖索引、辅助索引、唯一索引、Hash索引、B-Tree索引……”是,这导致了面试过程中的尴尬局面。
很多人可能会抱怨“面试中造火箭,工作中拧螺丝,很多知识都是为了面试而学,工作中根本不需要!”"。好在MySQL中的索引不仅是面试必备的知识,也是工作中最常用的必备技能。在我看来,索引是MySQL最具性价比的部分。
由于MySQL支持多种存储引擎,不同存储引擎的实现略有差距。如果下面的索引中没有特殊的语句,默认是指InnoDB存储引擎。
一、底层数据结构
首先,索引是高效获取数据的数据结构。就像书中的目录一样,我们可以通过它快速定位数据的位置,从而提高数据查询的效率。MySQL中有很多关于索引的术语和概念,初学者很容易混淆。为了便于理解,我设置了一个表格,试图从具体案例中解释清楚这些概念是什么。
散列索引
如上所述,索引是一种可以提高查询效率的数据结构,可以提高查询效率的数据结构有很多,比如二叉查找树、红黑树、跳表、Hash表等。在MySQL中,B树和哈希表被用作索引的底层数据结构。
需要注意的是,MySQL并没有明确支持Hash索引,但作为一种内部优化,它会自动为热数据生成Hash索引,也称为自适应Hash索引。
哈希索引可以在等价查询中定位时间复杂度为O(1)的数据,非常高效,但不支持范围查询。这种数据结构将用于许多编程语言和数据库,例如Redis支持的Hash数据结构。结构如下:

二叉树索引
b树(多路径搜索树,不是二进制)是一种常见的数据结构。使用B树结构可以显著减少定位记录时的中间过程,从而加快访问速度。
B-Tree是基于B-tree升级的树形数据结构,常用于数据库和操作系统的文件系统。B树的特点是能保持数据稳定有序,其插入和修改具有相对稳定的对数时间复杂度。b树元素是从下往上插入的,和二叉树正好相反。
MySQL索引的实现也是基于这种高效的数据结构。具体数据结构如下:
首先我想说清楚,B-Tree,B-tree和B-tree不应该混为一谈。首先,B树是一个B树。中间的“-”是中间的破折号,不是减号。没有“B减树”这样的数据结构。其次,B树和B树在实现索引时有两个区别,如下图所示。
B树只在叶节点存储数据,而B树数据存储在每个节点。
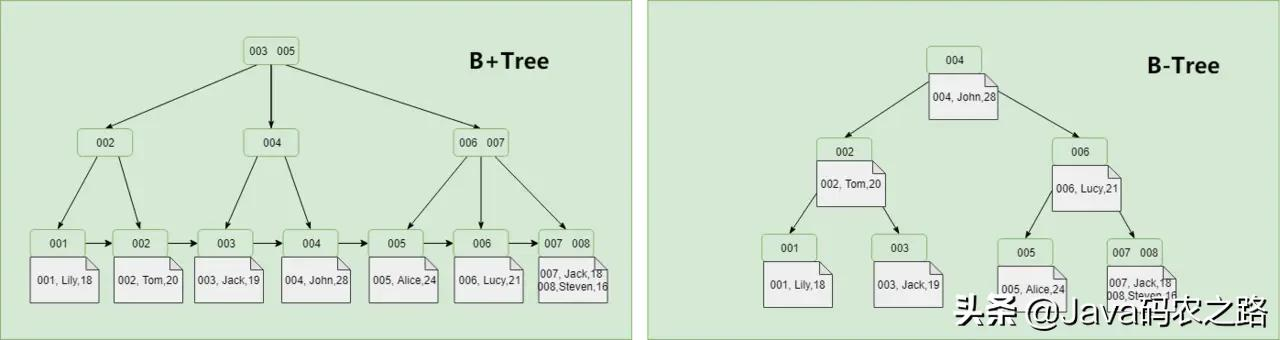
btree的叶节点通过指针链接,所有数据都可以通过遍历叶节点得到。
b树是一种神奇的数据结构,用在语言上可能有点难。感兴趣的同学可以点击文末的数据结构可视化工具,经过一些操作就会有所收获。下图为B树的数据插入方式(自下而上)。
二,数据组织方式
根据数据的组织方式可以分为聚集索引和非聚集索引(也称为聚集索引和非聚集索引)。簇索引是根据每个表的主键构造一个B树,叶子节点存储整个表的行记录数据。聚在InnoDB
簇索引和主键索引概念等价,MySQL中规定所以每张表都必须有主键索引,主键索引只能有一个,不能为null同时必须保证唯一性。建表时如果没有指定主键索引,则会自动生成一个隐藏的字段作为主键索引。与之对应的则是非聚集索引,非聚集索引又可以称之为为非主键索引,辅助索引,二级索引。主键索引的叶子节点存储了完整的数据行,而非主键索引的叶子节点存储的则是主键索引值,通过非主键索引查询数据时,会先查找到主键索引,然后再到主键索引上去查找对应的数据,这个过程叫做回表(下文中会再次提到)。
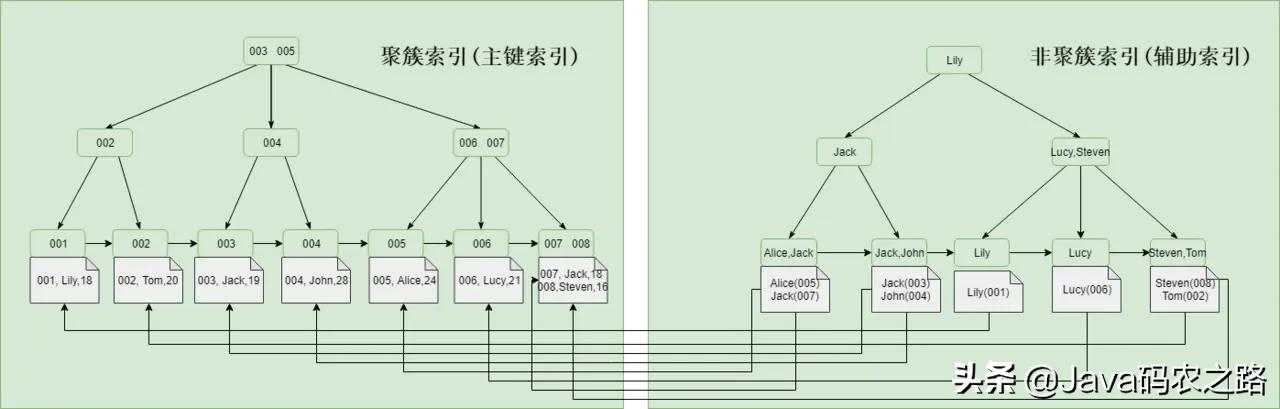
需要补充的是MyISAM中索引和数据文件分开存储,所有的索引都是非聚簇索引。B+Tree的叶子节点存储的是数据存放的地址,而不是具体的数据 。

三,包含字段个数
为了能应对不同的数据检索需求,索引即可以仅包含一个字段,也可以同时包含多个字段。单个字段组成的索引可以称为单值索引,否则称之为复合索引(或者称为组合索引或多值索引)。上文中演示的都是单值索引,所以接下来展示一下复合索引作为对比。
复合索引的索引的数据顺序跟字段的顺序相关,包含多个值的索引中,如果当前面字段的值重复时,将会按照其后面的值进行排序。
四,其他分类
唯一索引
唯一索引,不允许具有索引值相同的行,从而禁止重复的索引或键值。系统在创建该索引时检查是否有重复的键值,并在每次使用 INSERT 或 UPDATE 语句添加数据时进行检查, 如果有重复的值,则会操作失败,抛出异常。
需要注意的是,主键索引一定是唯一索引,而唯一索引不一定是主键索引。唯一索引可以理解为仅仅是将索引设置一个唯一性的属性。
覆盖索引
上文提到了一个回表的概念,即如果通过非主键索引查询数据时,会先查询到主键索引的值,然后再去主键索引中查询具体的数据,整个查询流程需要扫描两次索引,显然回表是一个耗时的操作。
为了减少回表次数,在设计索引时我们可以让索引中包含要查询的结果,在辅助索引中检索到数据后直接返回,而不需要进行回表操作。
但是需要注意的是,使用覆盖索引的前提是字段长度比较短,对于值长度较长的字段则不适合使用覆盖索引,原因有很多,比如索引一般存储在内存中,如果占用空间较大,则可能会从磁盘中加载,影响性能。当然还有其他原因,具体情况将会在下一篇文章中介绍。
六,总结
本文从不同维度介绍了MySQL中的索引,索引从不同维度划分可以有很多种名称,但是需要明确一个问题就是,索引的本质是一种数据结构,其他索引的划分则是针对实际应用而言。具体分类如下图所示:

目的是让大家对于索引有个初步且清晰的认识,解决What的问题。后续将会针对Why以及How,进行深入探讨,当然,首先应当能区分本章文章中讲述的概念性问题。
数据结构可视化工具: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
七、Q&A
1. 为什么MySQL索引使用B+Tree实现,而不是搜索二叉树,红黑树或者跳表?
这是一个综合性问题,远不止看起来那么简单,小伙伴们可以把答案写在留言区我们一起探讨,同样笔者将会在下一篇文章中重点介绍为什么,以及如何正确使用索引。