大家好,我是Python进阶者。前几天给大家分享了一些乱码问题的文章,阅读量还不错,感兴趣的小伙伴可以前往:盘点3种Python网络爬虫过程中的中文乱码的处理方法,UnicodeEncodeError: 'gbk' codec can't encode character解决方法,今天基于粉丝提问,给大家介绍CSV文件在Excel中打开后乱码问题的两种处理方法,希望对大家的学习有所帮助。
前言
前几天有个叫【RSL】的粉丝在Python交流群里问了一道关于CSV文件在Excel中打开后乱码的问题,如下图所示。
直接在Excel中打开csv文件,如下图所示:

分组问题:

看起来真的很大。对于爬行动物的初学者来说,这段乱码就在他们面前,就像一个路障。但是不要慌,边肖在这里为大家整理了两种方法,专门用于加扰CSV文件。希望你以后再遇到这个问题,可以在这里得到启发!
一、思路
其实解决问题的关键点在于一点,那就是编码转换。这里有两种方法。肯定还有其他方法。也欢迎大家在评论区给出建议。
二、解决方案
方法1:打开记事本
因为csv文件本质上也是文本文件,用记事本打开csv文件本身就可以直接打开,不会乱码。如果存储格式在网络爬虫中被指定为utf-8编码,用记事本打开csv文件没有问题。
f=open('filename.csv ',模式='a ',编码='utf-8 ')
Csvwriter=csv.writer(f),如下图所示:

因为我的源文件本身是韩文和日文,这是我看到的。上图不是随机的。不要误导大家,嘻嘻!
方法二:Excel转换
这个方法稍微复杂一点,但是更容易理解。对于初学者来说,还是可以接受的。可以直接在Excel中操作,步骤如下。
1)打开一个Excel文件,依次点击数据-来自文本/CSV,如下图所示。
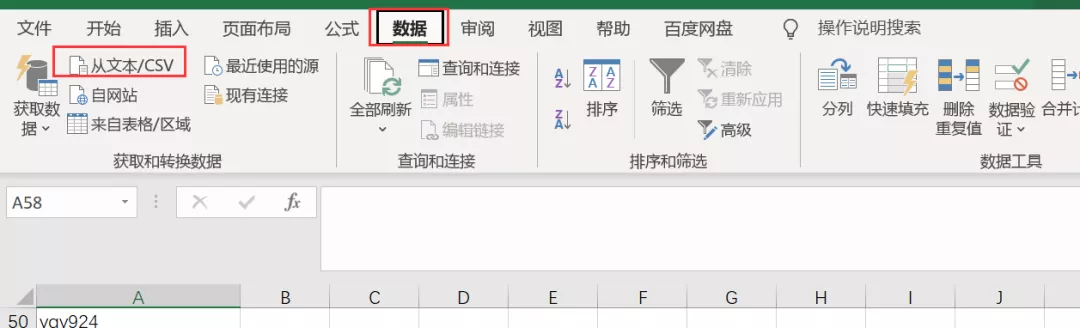
2)然后选择要加载的CSV文件,会自动弹出下图。

这里看到的是原始文件,真的乱码了。接下来,您需要稍微设置一下。
3)文件的原始格式设置为“无”或您的原始编码“UTF-8”;默认情况下,分隔符是逗号;数据类型检测的选择是基于整个数据集,最后选择右下方的负载,如下图所示。

4)稍等片刻,CSV文件会自动加载到Excel中,如下图所示。

因为我的源文件本身就是韩文和日文,我看到的就是这个。
5)在Excel中显示,如下图所示:

看起来还是很清爽。从而解决了中文乱码的问题。之后可以进一步导出到标准的Excel文件或者做数据处理。