

前言
本课程主要围绕移动互联网提供商拥有的大量用户时空数据,讨论能否通过这些足迹来预测用户线下的行为,甚至是一个城市的发展。
3个故事
1、谷歌流感
第一个故事是谷歌流感,也叫谷歌流感。谷歌流感是谷歌在2008年做的一项工作,在学术界和工业界都造成了很大的影响。突然我们发现,一家互联网公司居然开始介入疫情和区域发展相关的研究,文章作者除了一个贡献调查数据的人,都是谷歌的计算机科学家,没有任何传染病研究或城市研究的背景。这样的《自然》文章没有“公式”。他们是怎么做到的?为什么会有很多质疑和争议?
嗯,大家都用谷歌或者百度搜索,叫做Query,所以他们把大概5000万的主搜索数据和流感爆发的数据一一进行了相关性分析,筛选出了高度相关的关键词。主要关键词筛选出来后,以各种方式组合。如下图所示,Y轴代表准确率,X轴代表查询次数。组合成45个字,准确率最高,但不知道为什么。所以他们认为这45个关键词可以预测一个地区流感的发病趋势,这样就可以达到州一级的准确率,每个州都可以做出很好的预测。

下图是预测结果和实际结果的对比。黑色曲线代表预测值,红色曲线代表实际值。他们的预测可能比实际值早一到两周。这在当时引起了很大的轰动,这篇文章被广泛引用,但也为争议埋下了伏笔。谷歌在2008年进行的流感研究被认为是利用互联网和大数据研究区域性传染病的先驱。

2、谷歌失业
继2008年谷歌流感的工作之后,2009年,谷歌发送了一份关于他们使用搜索查看美国失业率的内部技术报告。如下图所示,黑色曲线代表美国被调查失业率,红色曲线代表谷歌搜索中与失业相关的词频变化。经过简单的时间序列回归和季节调整,他们发现它们之间有非常好的相关性。

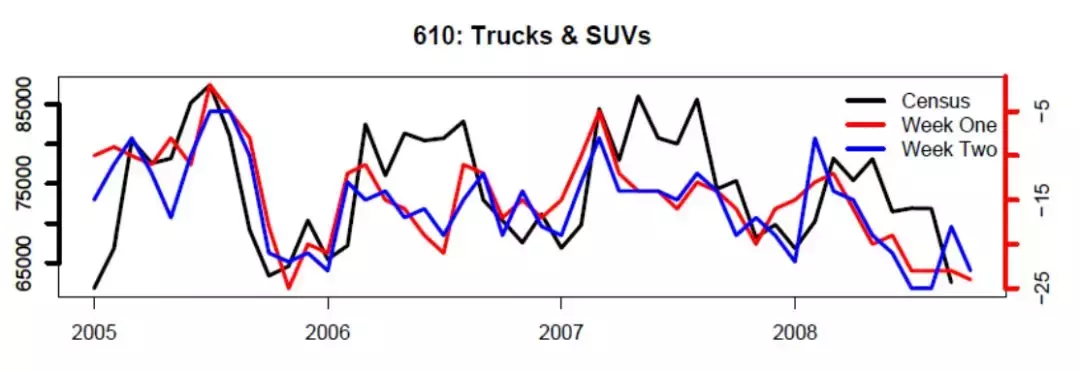
因此,谷歌认为,搜索词不仅可以预测流感,还可以预测当地经济的活力。而且不仅仅是宏观经济,还有微观经济,比如预测一辆车的销量,给公司提供商业建议。下图为谷歌预测的汽车销量,黑线为官方统计。然而,他们在文章中特别强调的是,谷歌预测现在,从不强调预测未来。
3、Google Culture
提到谷歌在经济领域的研究就不得不介绍谷歌的首席经济学家Hal Varian。Hal Varian在经济学界是一个先锋性人物,他最早关注了信息经济学以及网络经济学,写过一本名叫Information rules: a strategic guide to the network economy的重要著作。
Hal Varian2007年全职加入谷歌任首席经济学家,但早在2002开始就参与谷歌的很多研究与决策,通过经济手段优化拍卖机制,改善了谷歌的竞价排名。也在谷歌做过一些计量经济学的分析,包括公司的战略合作,还有公共政策。
谷歌做的很多工作看上去并不能够给谷歌带来商业上的直接收入,比如说流感预测、宏观经济预测,但是却在公众形象和政府关系产生了重要影响。
2011年,谷歌开始进行图书计划,基于所有电子化书籍整理成一个数据库,并开发一套算法,用以统计历史长河中词频的变化。谷歌图书计划在当时(2011年)一共电子化了500多万本书,约占人类全部出版物的4%。他们做了大量的工作,但文章写得很轻松,以图为主,我们可以来看一下他们的工作。
他们认为历史的演变会体现在出版物词频的变化上,通过一些关键词可以看出这种趋势。他们认为书籍中的词频能成功反映三次大流感的爆发,还有世界政治格局的演变,像所谓的南北问题,有神论和无神论。包括男性和女性这两个词,男性的词频在下降,女性在上升,这对应了女权主义的崛起。通过这种方式可以很好地刻画历史长河中文化的演变。
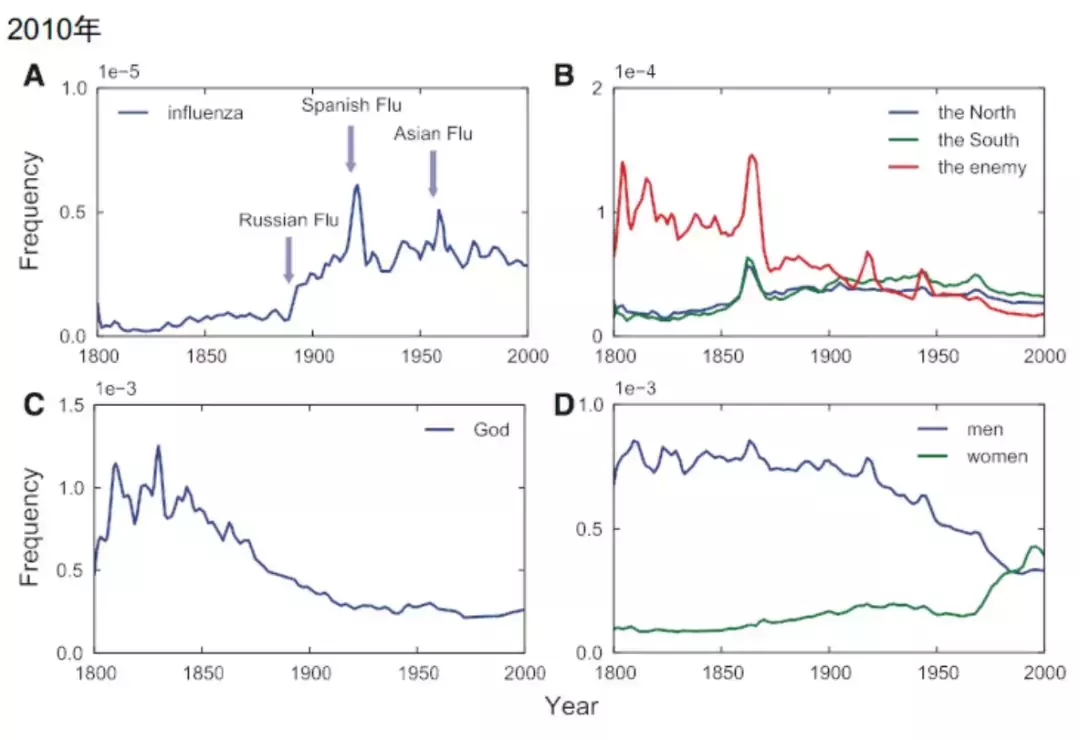
下图是wwdxlz(讲课老师)当时用谷歌的数据做的纽约、伦敦、巴黎和罗马四个城市200年间词频的变化图,可以看一个城市的兴衰和演变。可以看到,很明显的现象是罗马从1800年开始慢慢地衰落,这与大家的认知吻合,罗马在世界经济和文化中的地位正在减弱;巴黎不怎么变,还是比较稳定;但是这里面有两个在跃升的,一个是伦敦是稳步上升,而纽约有了大幅度地飞跃,这与整个经济和文化的中心从欧洲往美国转移有很大关系。
图上有两条灰色的线,对应的是纽约的多情的宝贝,欧洲城市的低谷,这其实是因为在两次世界大战期间,欧洲是主战场,战争摧毁了大量的城市,一下子跌入一个谷底,而美国那时候开始崛起。

4个特征
以上的三个故事,有这么四个特征,这些特征也是所有这一类研究的特点,同时也是很多人批判他们的原因。
1、只关注词频(Query)在时间序列上的变化;
2、有些带有的空间位置(不同区域的流感,不同地区的失业率);
3、预测当下,而非未来;
4、需要基于调查数据(Survey data)验证。
所以有很多人认为,大数据其实并没有发挥它的优势,只不过是做实了我们之前的一些研究而已。还有的人认为,其实数据粒度还可以做到很细,但是谷歌并没有做到。
我之前也这样认为,但是后来我在业界实习之后才发现,并不是谷歌做不到,事实上很可能他们已经做了,但并不会公开地对学术界或公众去讲,因为这会牵涉到个人的隐私。比如说每个人有一个ID,谷歌检测到他是不是检索过流感或者疾病爆发的关键词,这样可以很精准地刻画一个人的行为,但如果把这些数据公布出去,是一个非常敏感的事情。
批判
1、学界批判
对于“大”数据,大家可能多多少少都听过来自各方面的批判,但其中比较重要的是2014年Science的一篇文章TheParable of Google Flu: Traps in Big Data Analysis,四个作者都是相关领域最资深的学者,他们的批判在某种程度上也可以认为是学术界和工业界的大战。
这几位学者发现,Google Flu总是高估流感的实际情况,2011-2012这两年里,Google Flu在108周里有100周是高估的。如果这只是一个质疑的话那还好说,他们提出了一个更尖锐的质疑。如果只用调查数据(CDC有关于流感的调查)做一个滞后两期的模型,来进行预测,这个模型的结果比谷歌还要准。如下图所示。
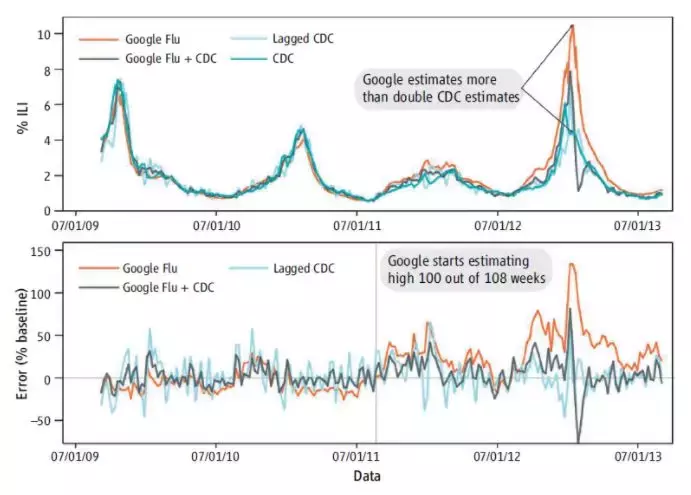
Google Flu与CDC的比较,Lagged CDC比Google Flu效果更好 (参考文献[7])
后来这几位学者就针对大数据的研究提了几个原则:
1、透明性和可重复性;
2、理解未知而非已知;
3、调查方法稳定性和一致性。
2、个人看法
(1)相关性和因果性问题
比如我们观测到一个地区如果其警察数量多,往往犯罪率也高。但是我们并不能因此得出一个结论:警察导致犯罪。再比如我们观测到一个地区消防员数量越多,森林火灾越多,但也是不能说是消防员导致了火灾。
但是我觉得在数据时代其实是更加好去解释这个问题,因为传统经济学方法都是在找试验,无论是工具变量法还是双重差分,都想构造出一个实验组、一个对照组,看看它们的区别。但是在很多数据驱动的公司里面,这已经是一个非常容易而且非常现实的工作,比如说现在很多互联网公司做的都是灰度发布,每次发布产品的时候,不是推给我的全部用户。
我会给A类用户推这种版本,我给B类用户推另一个版本,我看哪个比较受欢迎,最后会选择受欢迎的那个产品。所以像我们之前做的很多的对于经济、人口、政策的研究,都可以基于这些方式去做实验。如果你有比较好的实验和设计的话,就可以比较容易去解决因果和相关的问题。在数据时代是更容易去做这些试验的。
(2)样本的偏差问题
关于样本的偏差问题,这也是很多人质疑的。比如在研究一个问题时,谷歌就只有谷歌的用户,百度就只有百度的用户,微博就只有微博的用户,这就是一个样本选择偏差。其实这背后有两个问题:一个是研究的问题是什么?如果问题本身可以通过这个样本涵盖,那这并不构成问题。第二个可以结合一些调查数据对于“大”数据进行校准。而且随着全民移动的互联网化、物联网化,这种问题肯定是越来越好解决。
今天分享的内容是这些,大家还可以思考以下问题,是否能通过大数据评估一个地区(城市)的发展情况,无论是宏观经济、人口的、政策的;这种数据源与传统的统计调查经济普查、人口普查,以及对传染病的调查究竟有什么不同,应该如何使用?大数据的边界在哪里?
参考文献
1. Ginsberg,J., Mohebbi, M. H., Patel, R. S., Brammer, L., Smolinski, M. S., &Brilliant, L. (2009). Detecting influenza epidemics using search engine querydata. Nature, 457(7232), 1012-1014.2. Choi,H., & Varian, H. (2009). Predicting initial claims for unemploymentbenefits. Google Inc, 1-5.3. Choi,H., & Varian, H. (2012). 8Predicting the present with google trends.Economic Record, 8(s1), 2-9.4. Michel,J. B., Shen, Y. K., Aiden, A. P., Veres, A., Gray, M. K., Pickett, J. P., ...& Aiden, E. L. (2011). Quantitative analysis of culture using millions ofdigitized books. science, 331(6014), 176-182.5. Lazer,D., Kennedy, R., bzdlb, G., &Vespignani, A. (2014). The parable of GoogleFlu: traps in big data analysis. Science, 343(14 March).
作者:yxdhf编辑:Yiri
课程地址:
https://campus.swarma.org/gcou=10069
关注集智AI学园公众号
获取更多更有趣的AI教程吧!
搜索微信公众号:swarmAI
集智AI学园QQ群:426390994
学园网站:campus.swarma.org
商务合作和投稿转载|swarma@swarma.org