00-1010图的遍历类似于树的遍历。我们希望从图中的某个顶点开始,访问图中的所有其他顶点,并使每个顶点只被访问一次。这个过程被称为图的遍历图。
我们讲了树遍历的四种方案,应该说都没问题。毕竟只有一个根节点,从这个根节点开始遍历,其他所有节点只有一个平滑的季节。但是图要复杂得多,因为它的任何一个顶点都可能与所有其他顶点相邻,很有可能沿着某一条路径搜索之后,会回到原来的顶点,但是有些顶点还没有遍历完。因此,我们需要在遍历过程中标记访问过的顶点,避免在不知道的情况下多次访问。具体的方法是设置一个被访问的访问数组[n],其中n是图中的顶点数,初始值为0,访问后设置为1。其实这在小说中经常看到。一群人在迷宫中迷了路。为了避免反复尝试寻找出路,他们会在十字路口用刀刻上记号。
对于图的遍历,如何避免因循环而陷入无限循环,需要科学设计遍历方案。通常有两种遍历顺序方案:深度优先遍历和广度优先遍历。
00-1010 Depth_First_Search,也称为深度优先搜索,简称DFS。它的具体思路就像我刚才提到的找钥匙方案。无论你从哪个房间开始,比如主卧,然后从房间的某个角落开始,寻找角落、床头柜、床、床、衣柜、衣柜、前置电视柜等。在房间里一个接一个,以免错过任何死角。所有抽屉和储藏柜都被搜查过了。比喻颠倒过来,然后寻找下一个。
让我们玩一个游戏来更好地理解深度优先遍历。
假设你需要完成一项任务。您需要遍历图的所有顶点,并在如下图左侧所示的迷宫中从顶点A开始标记它们。注意不要简单地看这样的计划,而是尽可能现实地在只有高墙和通道的迷宫中完成任务。
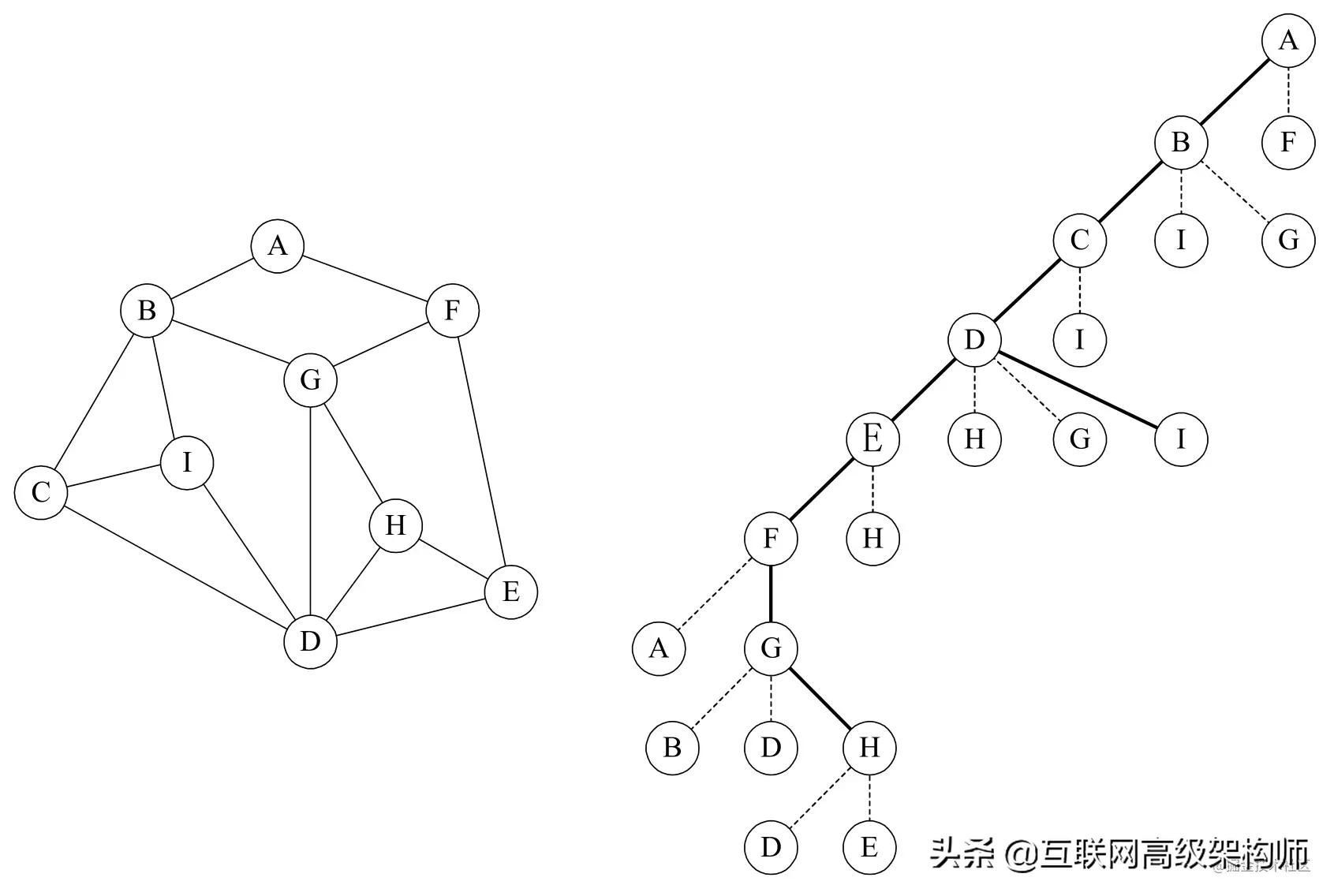
显然,我们需要策略,否则,如果我们想在这个连接良好的渠道中跑来跑去,我们只能碰运气来完成任务。如果你研究过深度优先遍历,这个任务并不难完成。
首先我们从顶点A开始,标记过去之后,有两条路通向B和f,我们给自己定了一个原则,就是不遇到重复的顶点时,总是向右走,这样就到达了顶点B,全程见图7-5-2右图。这时发现有三个分支通向顶点C、I和G,右手原理将我们引向顶点C,这样,我们沿着右手通道一直走到f的顶部,当我们仍然选择走过右手通道时,我们发现我们已经走回了顶点A,因为我们在这里做了一个标记,表示我们已经通过了。这时,我们回到顶点F,从右边进入第二个通道。在G的顶点,它有三个通道。我们发现B和D都已经过去了,所以我们走到H,当我们面对通向H的两个通道D和E时,我们会发现它们都已经过去了。
我们此时是否已经遍历了所有顶点?没有。可能有很多分支我们还没有到达,所以我们会按原来的路线返回。在顶点h,没有未通过的通道,返回到g,没有未通过的通道,返回到f,没有通道,返回到e,有一个通道验证后通向h,然后返回到顶点d,此时,仍有三个通道未通过,一个接一个,h通过了,g通过了,我,哦,这是一个新的顶点,没有标记,快点。往回走,直到回到顶点A,确保已经完成遍历任务,找到所有9个顶点。
反应快的同学肯定会觉得深度优先遍历其实是一个递归的过程。如果他们比较敏感,就会发现转换成如图7-5-2所示的右图后,就像是一棵树的序曲遍历。是的,它是。它从图中的一个顶点V开始,访问这个顶点,然后从V的未访问的相邻点以深度优先级遍历图,直到图中所有具有V路径的顶点都被访问。事实上,我们在这里讨论的是一个连通图。对于一个不连通图,我们只需要经历其连通分量的深度优先遍历,也就是在前一个顶点的深度优先遍历之后,如果图中还有未被访问过的顶点,那么选择图中另一个未被访问过的顶点作为起点,重复上述过程,直到图中所有的顶点都被访问过。如果我们使用邻接矩阵法,代码如下:
typedef int布尔值;/*布尔值是移动的犀牛类型,其值为真或假*/
布尔访问了[MAX];/*访问标志数组*/
/*邻接矩阵的深度优先递归算法*/
无效的DFS
{
int j;
已访问[i]=真;
printf ('%c ',g . vexs[I]);/*打印顶点,或执行其他操作*/
for(j=0;j G.numVertexesj)
if (G.arc[i] [j]==1!参观[j])
DFS (Gr,j);/*递归调用*/
}
/*邻接矩阵的深度遍历操作*/
空DFSTraverse (MGraph G)
{
int I;
for(I=0;i G.numVertexes我
) visited [i] = FALSE; /*初始所有顶点状态都是未访问过状态*/ for ( i = 0; i < G.numVertexes; i++ ) if ( !visited[i] ) /*对未访问过的顶点调用DFS,若是连通图,只会执行一次*/ DFS (G, i); }代码的执行过程,其实就是我们刚才迷宫找寻所有顶点的过程。
如果图结构是邻接表结构,其DFSTraverse函数的代码是几乎相同的,只是在递归函数中因为将数组换成了链表而有不同,代码如下。
/*邻接表的深度优先递归算法*/ void DFS ( GraphAdjList GL, int i ) { EdgeNode *p; visited[i] = TRUE; printf ( "%c "GL->adjList [i] .data) ; /* 打印顶点,也可以其他操作 */ p = GL->adjList[i].firstedge; while (p) { if (!visited[p->adjvex]) DFS(GL, p->adjvex) ; /*对为访问的邻接顶点递归调用*/ p = p->next; } } /*邻接表的深度遍历操作*/ void DFSTraverse ( GraphAdjList GL ) { int i; for ( i = 0; i < GL->numVertexes; i++ ) visited [i] = FALSE; /*初始所有顶点状态都是未访问过状态*/ for ( i = 0; i < GL->numVertexes; i++ ) if ( !visited[i] ) /*对未访问过的顶点调用DFS,若是连通图,只会执行一次*/ DFS ( GL, i ); }对比两个不同存储结构的深度优先遍历算法,对于n个顶点e条边的图来说,邻接矩阵由于是二维数组,要查找每个顶点的邻接点需要访问矩阵中的所有元素,因此都需要O(n*2)的时间。而邻接表做存储结构时,找邻接点所需的时间取决于顶点和边的数量,所以是O(n+e)。显然对于点多边少的稀疏图来说,邻接表结构使得算法在时间效率上大大提高。
对于有向图而言,由于它只是对通道存在可行或不可行,算法上没有变化,是完全可以通用的。这里就不再详述了。
作者:有出路链接:https://juejin.cn/post/6996606397337042951来源:掘金