全文共有2468个字,预计学习时间需要7分钟

Dabl是数据分析基线库的缩写。 Dabl背后的理念是自动执行监控学习,从而减少常见任务的模板。
建立预测模型时,数据需要进行清理、分析,通过不同的参数调整运行各种模型,得到最佳的精度。 虽然这样的操作需要多行代码和人为操作,但是通过dabl处理,只需要几行代码就可以节省处理大量数据的时间和开销。
这个库的主要目的不是每次重复同样的操作步骤,而是让数据科学家思考问题的说明,做出更多的惯例分析。 Dabl从scikit-learn和auto-sklearn那里得到了灵感。
安装和输入
只需输入一个库,该库dabl就可以完成所有必要的任务。
! pip安装数据库
导入数据库获取数据
Dabl中几乎没有可以直接加载和使用的数据帧。 也可以使用普通的Pandas样式读取外部数据。 在包括成人人口普查数据集在内的数据框架中工作。
df=dabl.datasets.load_adult (
DF .头() )

数据清理
数据清理是第一步。 Dabl将检测数据集中的数据类型,并尝试应用相应的转换。 Dabl的目标是为数据可视化和模型提供足够的数据清理。 如果需要,还可以执行自定义清理。
dabl.clean(x,type _ hints=无,return _ types=假,target _ col=无,伯博斯=0)
X :数据帧
type_hinta:语义类型(连续、类别、顺序、文本等)检测失败时
return_type:是否返回估计的类型
target_colstring:Target列永远不会被删除
DATA_clean=dabl.clean(df,类型_ hints={ ' capital-gain ' : ' continuous ' } )
数据清除

数据集说明
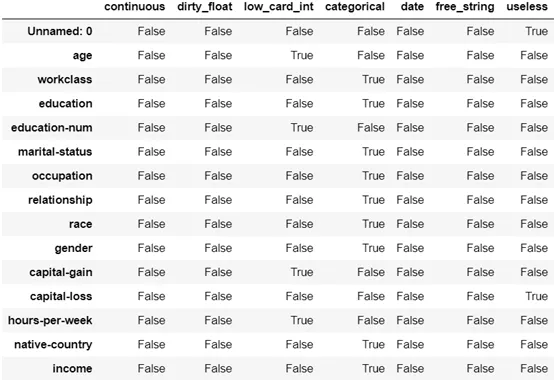
从以前的意义上讲, info ) )应用于数据集后,将得到初始分析。 也可以使用dabl.data _ types ) )来预测各列的数据类型。
dabl.detect_types(x,type _ hints=无,max _ int _ cardinality='自动',dirty _浮点_阈值=0.9,
Dabl .检测类型(DF )
探索性数据分析
dabl.plot ()可以迅速分析数据。 但是,dabl并不保证表现出数据的所有有价值的部分。 这提供了重要的特性、相互作用、问题的难易程度等非常高的见解,人们必须再次执行传统的定制绘制进行具体的分析。
dabl.plot(x,y=None,target_col=None,type_hints=None,scatter_alpha='auto ',scatter _ size=' aaane ),其中,目标-类型。
dabl.plot(df,目标_科尔=' income ' )

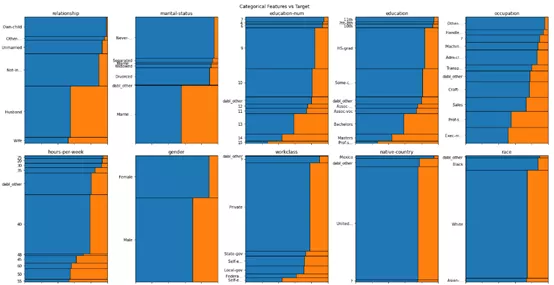
不可思议吧,只用了半行代码就得到了相当不错的结果。
模型构建
Simplecclassifier 被用来寻找最佳拟合模型,它对子采样数据应用几个基线。dabl的灵感来源于scikit-learn(由于dabl受到scikit-learn的启发),它帮助我们指定数据,以符合 scikit-learn 风格。方法有两种:
model = dabl.SimpleClassifier(random_state=0) X = data_clean.drop("income", axis=1) y = data_clean.income model.fit(X, y)或者:
model = dabl.SimpleClassifier(random_state=0).fit(data_clean,target_col="income")
输出:
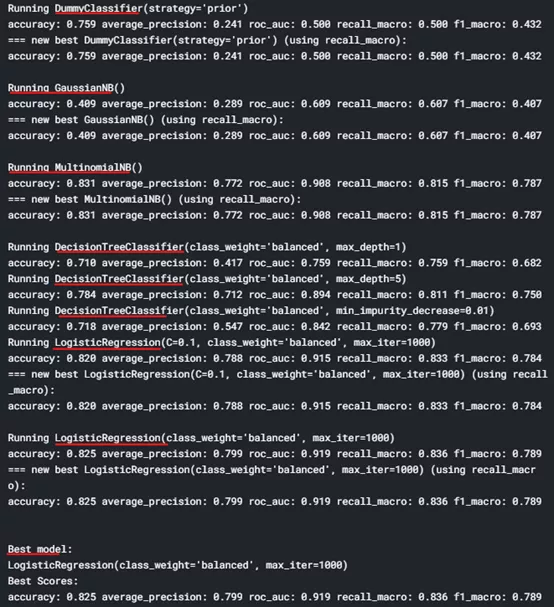
正如你所看到的,它通过不同的参数调整应用了几个模型,找到最佳拟合模型和准确率。Simplecclassifier 还可以进行预处理缺失值插补和一次性编码等预处理,可以使用 dabl.explain ()检查模型:
dabl.explain(model)

Dabl的局限性
现在,dabl仍不能用于处理文本数据、时间序列数据、神经网络模型,图像、音频和视频数据也完全超出了应用范围。其未来目标是:
· 现成的可视化
· 模型诊断
· 高效模型搜索
· 类型检测
· 自动预处理
· 良好的管道组合
真的需要人类数据科学家吗?
Dabl 非常有趣,并且是自动化的,但是它仍然处于开发阶段,只有非常少的特性和功能。笔者建议你浏览一下dabl提供的API列表。我个人任务部署一个功能齐全、个性丰富的版本仍然需要很长时间,如果它能完成,业界必须信任和接受它。
数据科学就是这样一个领域,业界每天都会生成一个独特的数据集和问题陈述/需求,因此在某个时候,人类的干预是必要的。自动化数据科学将是未来的趋势,但不会立刻到来,所以你可以专注于提高技能或学习数据科学。

图源:《福布斯》
记住,一定要提高自己的技能,每当你认为自己已经掌握了足够的知识时,就把这篇文章当做一个警钟,它可以让你不停地学习新的技能。
留言点赞关注
我们一起分享AI学习与发展的干货
如转载,请后台留言,遵守转载规范