安妮zxdgs起源于奥菲神庙。
由qubit |微信官方账号QbitAI制作
如何评价一个神经网络的泛化能力?
比利时鲁汶天主教大学的一项研究发表在ICML 2019年关于识别和理解深度学习现象的研讨会上。
指出网络的泛化能力可以通过“层旋转”来判断。
所谓层旋转是指神经网络中各层的权向量与初始化之间夹角的余弦变化,研究者可以将其作为衡量泛化性能的指标。
研究人员在训练时公布了控制层旋转工具的代码,表明这项工作“可以大大降低目前调整超参数的难度”:
也就是说,神经网络的最佳性能可以通过最小超参数调整来获得。
在Reddit论坛上,有人指出这是一个“超级有趣的实证结果”,也有人说这个研究启发了很多新的思考。

00-1010在论文中,层旋转:a是深度网络中令人惊讶的强大概括指标?研究详细解释了图层旋转背后的探索之路。
神经网络的泛化能力受训练它的优化程序的影响,因此确定该程序中哪些因素影响泛化是很重要的。
本文研究人员提出了一种新的算法:layca(层级控制的权值旋转量),可以通过网络各层的学习速率参数直接控制神经网络的优化算法,进而控制层的旋转。
也就是说,采用Layca算法,通过其学习速率参数可以控制每层网络中每一步的权重旋转。
Layca算法的工作流程如下:

研究人员表示,有了这种新算法,可以达到明显的控制效果,同时泛化能力也会有很大差异,准确率相差30%。
随后,他们使用Layca进一步研究层旋转架构,并开发工具来监控和控制层旋转。
研究人员使用SGD(随机梯度下降)作为默认优化器,使用Layca分别改变相对旋转速度和全局旋转速度的值,研究了5种不同网络架构和数据复杂度的神经网络,具体如下:

他们绘制了不同层旋转速率下层旋转曲线(CFR)和相应测试精度()之间的关系。
下图中横轴代表迭代次数,纵轴代表夹角余弦,曲线颜色由浅到深代表网络的最后一层和第一层。最终结果如下:
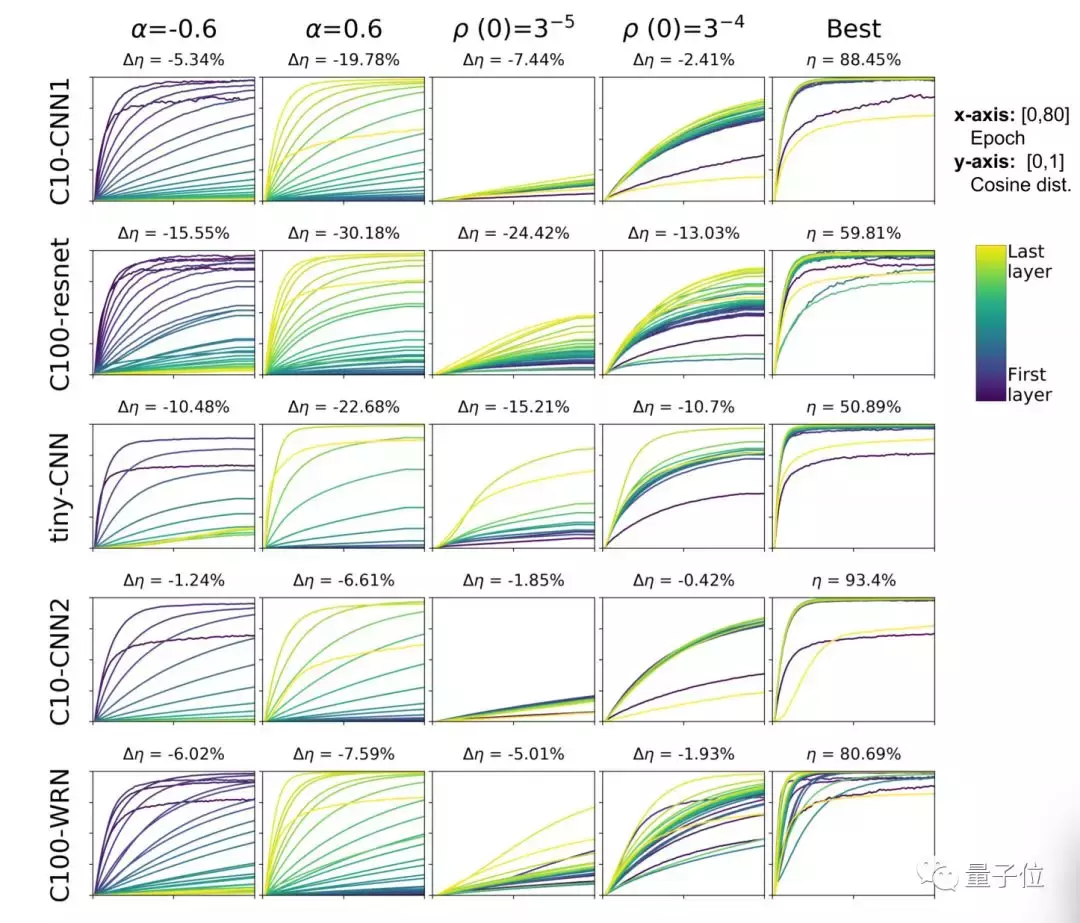
可以看出,每层的层旋转越大,神经网络的泛化能力越好。
因此,研究人员认为,层旋转的指标可以用来直接判断网络的泛化能力。
层旋转有什么用
之后,除了Layca,研究人员还用SGD做了类似的实验。根据实验结果,得出几个结论:对于SGD学习率
学习速率参数直接影响图层旋转速率和更新大小。
从以下五个任务中SGD训练时不同学习速率对层旋转曲线影响的实验结果可以看出,测试精度随着层旋转而增加,到临界点后开始下降。

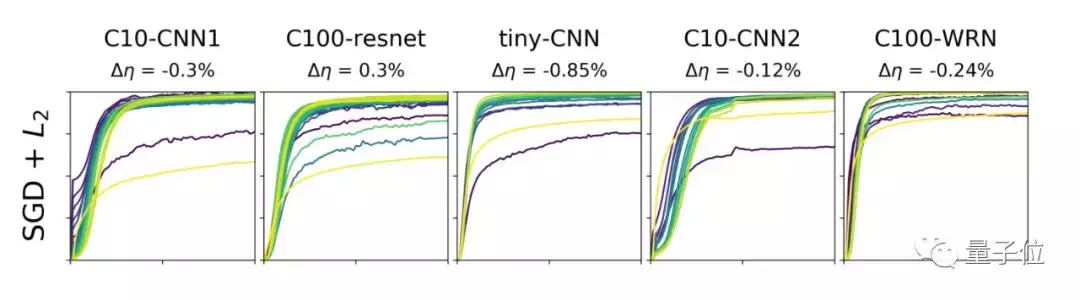
为了减轻重量
权重的衰减范数将增加由给定训练步骤引起的旋转。根据下面的实验结果可以看出,初始化时所有层的权重都达到了1的余弦距离,得到的测试性能与使用Layca得到的测试性能相当。
用于学习速率预热
学习率高会产生突然的层轮换,不会影响训练损失。
在学习速率预热方面,研究人员使用ResNet-110在CIFAR-10数据集上进行实验和训练。使用前
热策略是以小10倍的学习速率开始,线性增加逐渐达到指定的最终学习率。结果如下图:

SGD产生不稳定的层旋转,始终转化为无法提高训练精度。使用预热可以大大减少这些不稳定性,在Epoch超过25之前,训练京都没有显著提高。
而Layca表现更优。归功于Layca的控制能力,它稳定性较高,并且在不需要预热的情况下达到高泛化性能。
对于自适应梯度法
研究者们基于ICLR 2015论文《A method for stochastic optimization》中的算法,在C10-CNN1任务上做了实验。
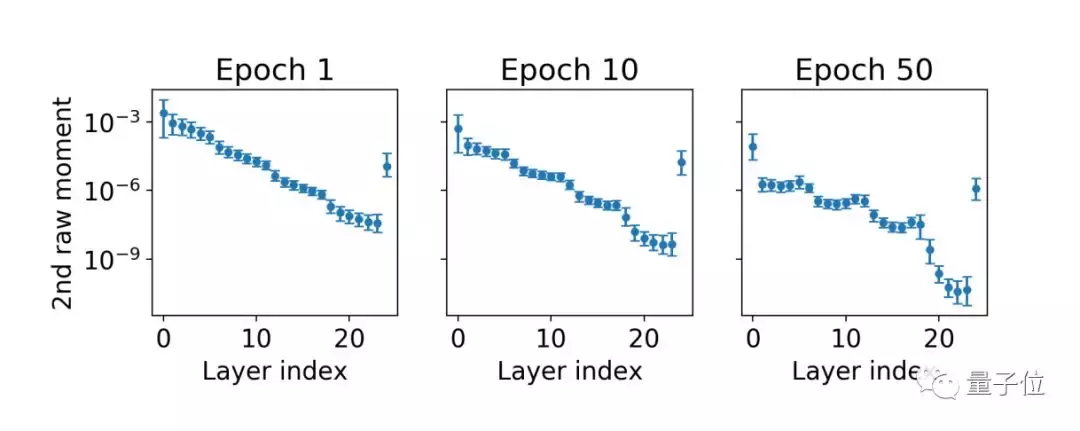
根据第10,第50和第90百分位每个层的状况可以看出,自适应梯度方法可能对层旋转产生巨大影响,自适应梯度方法使用的参数级统计数据主要在层之间变化,而在层内可忽略不计。
另外,对比自适应梯度法在训练前面的5个任务和自适应梯度法层旋转与SGD诱导层旋转的结果,可以发现,自适应梯度法能够让Layca达到SGD的泛化能力。

根据自适应梯度法、SGD+权重衰减和SGD+L2正则化在5个训练任务上的表现得出,SGD可以通过Layca实现自适应梯度法的训练速度。

对于中间层特征
那么,基于这些层旋转和各属性之间的联系,如何去具体的解释层旋转呢?
研究者们做了另一个实验,在一个简化的MNIST数据集上训练多层感知机(MLP),从相同的初始化状态开始,我们用Layca训练四种学习率不同的网络,让四种不同的层旋转配置均达到100%的训练准确度,同时拥有不同的泛化能力。
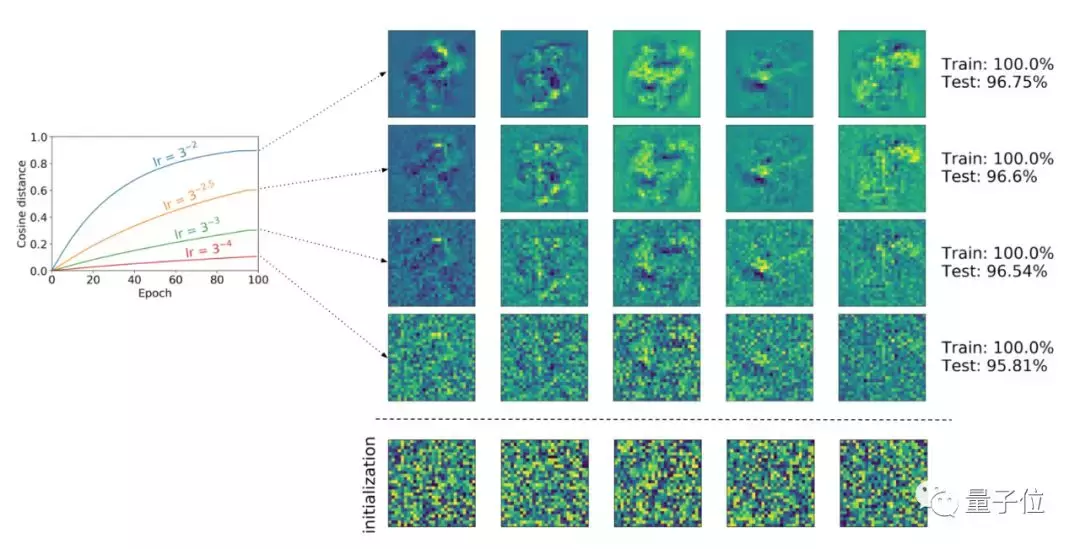
将图旋转对中间层特征的影响画出来就会发现:
层旋转不会影响学习哪些特征,而是影响在训练过程中学习的程度。层旋转越大,特征越突出,初始化可检索的越少,而当层旋转接近1的时候,网络的最终权重消除了初始化的所有残余。
层旋转与特征学习程度之间的这种联系表明:完全学习中间层特征对于达到100%的训练准确性是不必要的,但训练过程如果完全学习了中间层特征,可以产生更好的泛化性能。
传送门
Layer rotation: a surprisingly powerful indicator of generalization in deep networks?
https://arxiv.org/abs/1806.01603v2
代码:
https://github.com/ispgroupucl/layer-rotation-paper-experiments
层旋转工具:
https://github.com/ispgroupucl/layer-rotation-tools
— 完 —
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态